
機械学習に至るまでのデータ作成が長かったな・・・やっとAIっぽいことができそう。
やっと訓練できるね。まずはscikit-learnで実際にどんなプログラムになるか見ていこう。
前回までに、scikit-learnのアヤメデータから機械学習アルゴリズムの訓練に必要なデータを作成することができました。


作成したデータを利用して、初めての機械学習を行ってみました。初めてのアルゴリズムは、比較的理解しやすそうな「k最近傍法(k-nearest neighbor algorithm)」というものを利用しました。
こんな人の役に立つかも
・機械学習プログラミングを学びたい。
・scikit-learnでk最近傍法を利用したい。
・アヤメのデータをk最近傍法で分類したい。
k最近傍法をプログラミング
毎回同様にまずはimportからアヤメデータの読み込みまで。X_train、x_test、y_train、y_testとアヤメのデータを訓練データとテストデータに分割します。
今回は、k最近傍法を使うので、scikit-learnのKNeighborsClassifierを読み込みます。
from sklearn.datasets import load_iris
from sklearn.model_selection import train_test_split
#k-最近傍法のimport
from sklearn.neighbors import KNeighborsClassifier
import numpy as np
#import matplotlib.pyplot as plt#今回は使わないよ
import pandas as pd
#import seaborn as sns#今回は使わないよ
panda_box = load_iris()
X = panda_box.data
y = panda_box.target
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size = 0.5, stratify=y)ここまでは前回までとほぼ同じだね。
次に、以下のプログラムのように、K最近傍法のオブジェクトというものを作成します。
#k-最近傍法のオブジェクトの宣言
knc = KNeighborsClassifier(n_neighbors = 1)kncという変数(好きな名前でOKです)にk最近傍法を入れて使います。「n-neighboes=」のところは今回は1とします。今回は、ここは1として進みます。
次に、k最近傍法へ訓練データを渡します。
#学習
knc.fit(X_train, y_train)k最近傍法の持つ、fitという機能で訓練データを訓練させます。簡単ですね~
ここまでで、アヤメの訓練データを学習したプログラムができました。kncというやつが勝手に訓練してくれたので、後はこいつにデータを入れて分類させます。
テストデータを1個だけ入れてみましょう。テストデータはX_testに75個入っているので、その最初の1個を使いますね。
#X_test[0]の中身
print(X_test[0])
#X_test[0]をnumpyの形にする。
test_data = np.array([X_test[0]])
#答えの確認
print(y_test[0])
#データの予測
print(knc.predict(test_data))X_test[0]とすることで一番最初のデータを指定できます。kncにデータを入れるため、大人の事情でnumpyの形に変換します。それは、「test_data」という名前の変数に入れています。
最後の、predict(test_data)が、テスト用データからアヤメの種類を求める機能です。
この答えが、y_test[0](テストデータの答えの最初のデータ)と一致していれば正解となります。
ほぼ正解となると思います。
このpredictは、一つのデータに対する答えを返してくれるのですが、すべてのデータ、こんかいは75個ありますので、そのすべてのデータをテストするのは、現実的ではないですね^^;
そこで、scoreという機能を使います。これを使うことで、75個すべてのテストデータの答えを確認して、その正解率を出してくれます。
#モデルの評価(75個すべての予測結果の正解率)
print(knc.score(X_test, y_test))今回は、次のように結果が出ました。
0.946666666666666794%正解しています。
train_test_splitで10回分割してみる
正解率が94%と出ましたが、今回のデータの分割の結果にすぎません。
そこで、train_test_splitの訓練データとテストデータの分割を10回行ってみることにしました。
#10回やってみて、平均の正解率をみてみる
#result = np.array([0., 0., 0., 0., 0., 0., 0., 0., 0., 0.])#zerosを使ったほうが短く便利
result = np.zeros(10)#↑と同じことを短い文字数で実現している。
#10回、「データを分割→学習→正解確率を得る」を繰り返す。
for i in range(10):
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size = 0.5, stratify=y)
knc.fit(X_train, y_train)
result[i] = knc.score(X_test, y_test)
#numpyの表示を小数点2桁までに変更
np.set_printoptions(precision=2)
print("10回の結果を表示")
print(result)Pythonのfor文を使いました。10回train_test_splitを呼び出し学習結果をresultという変数にひとつづつ入れていっています。
10回の結果を表示
[0.97 0.95 0.95 0.95 0.96 0.97 0.93 0.96 0.95 0.95]10回行うと、正解確率が高いときは97%、正解確率が低いときでも93%になります。
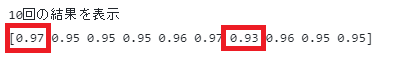
ということで、正解確率を平均しましょう。
print("10回の平均的な正解確率")
print("{:.2f}".format(result.sum()/10))10回の平均的な正解確率
0.95k最近傍法で、scikit-learnのアヤメのデータを分類させると大体95%の確率で正解する分類ができそうなことがわかりました!
まとめ:機械学習プログラミングの流れが把握できました
「アヤメデータの教師あり学習の分類をする」、という目標のもと、機械学習プログラミングで、アヤメの分類をすることができました。
今回の学習で、「データ構造の理解、分析」、「訓練用とテスト用にデータの分割」、「機械学習アルゴリズムへの学習、評価」という段階を具体的につかむことができました。
実際のところ、データ分割の方法を改善したり、機械学習のアルゴリズムをいろいろ試したりとまだまだやれることがありそうです。また、データを収集するという部分もいろいろ勉強が必要そうです。
次に、k再近傍法について、どうやって分類しているかを勉強しました。
