
データの分割で訓練データができた。これで機械学習のプログラムに学習ができるのかな??
もうできそうだけど、実は訓練データとテストデータの分けるポイントでもう一つ気をつけなければいけないことがあるよ。
こんな人の役に立つかも
・機械学習プログラミングを勉強している人
・前回の続きです
前回の記事はこちら

・機械学習プログラミングでStratifiedなデータ分割について知りたい
データのばらつき具合とは??
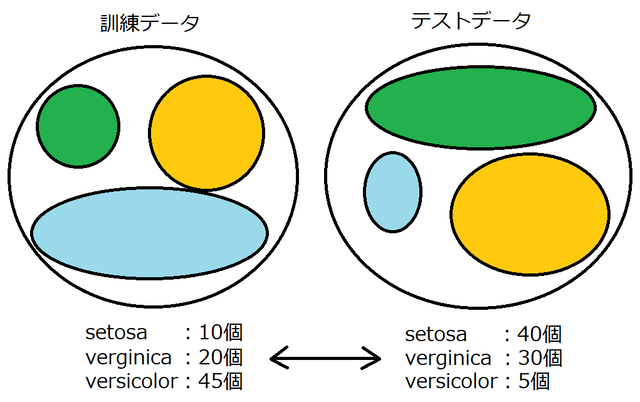
例えば、次の図のように、訓練データとテストデータで「setosa」のデータに偏りがあった場合、訓練は十分できているといえるか?という点に着目します。(緑色が「setosa」です)
実際にプログラムでデータの割合を確認してみます。
前回のプログラムを実行した最後に、次のようなプログラムを実行します。
このプログラムで、訓練データとテストデータに「setosa」「verginica」「versicolor」のデータがどれくらいの割合で含まれているかがわかります。
#データのばらつき具合の確認
print("訓練データのデータ割合")
print(np.unique(y_train, return_counts=True))
data, kosuu = np.unique(y_train, return_counts=True)
print('{:.2f}'.format(kosuu[0]/kosuu.sum()),
'{:.2f}'.format(kosuu[1]/kosuu.sum()),
'{:.2f}'.format(kosuu[2]/kosuu.sum()))
print("テストデータのデータ割合")
print(np.unique(y_test, return_counts=True))
data2, kosuu2 = np.unique(y_test, return_counts=True)
print('{:.2f}'.format(kosuu2[0]/kosuu2.sum()),
'{:.2f}'.format(kosuu2[1]/kosuu2.sum()),
'{:.2f}'.format(kosuu2[2]/kosuu2.sum()))このプログラムでは、y_train変数の中の「0」と「1」と「2」のデータ数がそれぞれいくつあるかをカウントしています。numpyのuniqueという機能で、含まれるデータの種類と、その数がいくつあるかを数えてくれます。
それぞれ、データの全体個数(kosuu.sum)をデータの数で割ることで、データの%を出しました。
実行結果(※train_test_splitの実行毎に変化します)
訓練データのデータ割合
(array([0, 1, 2]), array([23, 22, 30]))
0.31 0.29 0.40
テストデータのデータ割合
(array([0, 1, 2]), array([27, 28, 20]))
0.36 0.37 0.27今回の実行では、y_train変数の「setosa」「verginica」「versicolor」の割合は、
「setosa:31%、verginica:29%、versicolor:40%」となったようです。
一方で、y_test変数の「setosa」「verginica」「versicolor」の割合は、
「setosa:36%、verginica:37%、versicolor:27%」となりました。
訓練データとテストデータで「setosa」「verginica」「versicolor」のデータ数を同じ割合にしてあげることで、訓練とテストでデータの偏りをなくすことができます。
究極的にいうと、訓練データに「setosa」のデータしかなかったら、「versicolor」を予測できないように、訓練とテストで同じ割合のデータを持っておくことは、より正確に検証ができるようになるということです。
このようなデータをStratifyなデータ、というらしいです。仲間と「このデータってストラティファイ?(`・ω・´)キリッ」というために覚えましょう。
train_test_splitでstratifyなデータを作成
train_test_splitnには、「stratify=」というパラメータがあります。
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size = 0.5, stratify=y)stratifyの対象は答えのデータであるアヤメデータの「”target”」すなはち、先にyに入れてnumpyのデータにしているため、「y」になります。(答えのデータを訓練とテストで同じ割合とするため。)
print("stratify後の訓練データのデータ割合")
print(np.unique(y_train, return_counts=True))
data, kosuu = np.unique(y_train, return_counts=True)
print('{:.2f}'.format(kosuu[0]/kosuu.sum()),
'{:.2f}'.format(kosuu[1]/kosuu.sum()),
'{:.2f}'.format(kosuu[2]/kosuu.sum()))
print("stratify後のテストデータのデータ割合")
print(np.unique(y_test, return_counts=True))
data2, kosuu2 = np.unique(y_test, return_counts=True)
print('{:.2f}'.format(kosuu2[0]/kosuu2.sum()),
'{:.2f}'.format(kosuu2[1]/kosuu2.sum()),
'{:.2f}'.format(kosuu2[2]/kosuu2.sum()))次の結果のように、y_train、y_testと共に、「setosa」「verginica」「versicolor」の割合が同じ割合で分けられるようになりました。
stratify後の訓練データのデータ割合
(array([0, 1, 2]), array([25, 25, 25]))
0.33 0.33 0.33
stratify後のテストデータのデータ割合
(array([0, 1, 2]), array([25, 25, 25]))
0.33 0.33 0.33まとめ:訓練とテストデータの答えは同じ割合で分割する
train_test_splitという機能は、データ分割するためにはとても便利です。このような分け方をするためにプログラムを組んでいたら結構時間がかかってしまいますので^^;
今後、ホールドアウト法で訓練データとテストデータを分割するにはstratifyを指定していきたいです。
次は、k再近傍法という方法でアヤメのデータを分類することを学びました。

プログラムまとめ
アヤメのデータを読み込むところから、ホールドアウト法でstratifyなデータ分割をするところまで。
from sklearn.datasets import load_iris
from sklearn.model_selection import train_test_split
import numpy as np
import matplotlib.pyplot as plt
import pandas as pd
import seaborn as sns
panda_box = load_iris()
X = panda_box.data
y = panda_box.target
#stratifyを指定して学習データとテスト用データへ分割(半分の75個づつ)
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size = 0.5, stratify=y)
print("stratify後の訓練データのデータ割合")
print(np.unique(y_train, return_counts=True))
data, kosuu = np.unique(y_train, return_counts=True)
print('{:.2f}'.format(kosuu[0]/kosuu.sum()),
'{:.2f}'.format(kosuu[1]/kosuu.sum()),
'{:.2f}'.format(kosuu[2]/kosuu.sum()))
print("stratify後のテストデータのデータ割合")
print(np.unique(y_test, return_counts=True))
data2, kosuu2 = np.unique(y_test, return_counts=True)
print('{:.2f}'.format(kosuu2[0]/kosuu2.sum()),
'{:.2f}'.format(kosuu2[1]/kosuu2.sum()),
'{:.2f}'.format(kosuu2[2]/kosuu2.sum()))GitHubに、アヤメのデータ分割をする一連のサンプルプログラムをアップロードしました。ご参考ください。
