
前回は、k最近傍法というアルゴリズムを使ったね。
k最近傍法というアルゴリズムがどんな動きをしているのか、見てみよう。
前回、k最近傍法プログラミングの続きです。

前回は、プログラミングをまず記載しましたので、今回は、k最近傍法について勉強したことをつづりたいと思います。
こんな人の役に立つかも
・k最近傍法はどんなものか知りたい
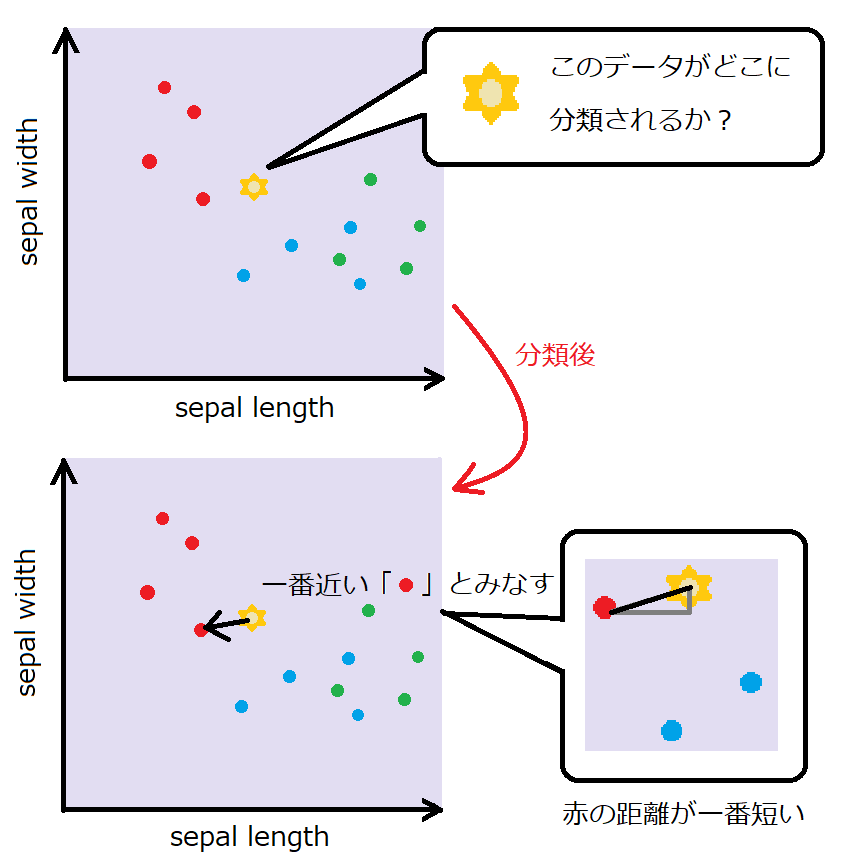
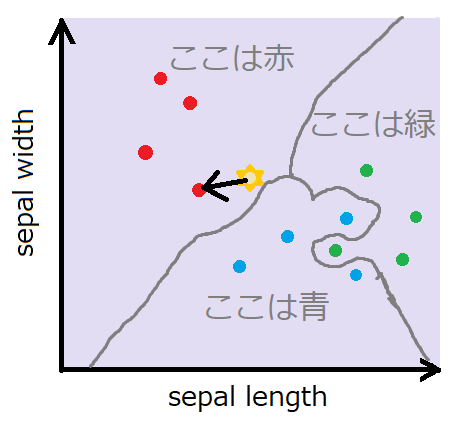
距離が最も近いものを選択する
k最近傍法は、一番距離が近いデータに分類します。
一番シンプルな2つの特徴量の場合で考えます。
次に、特徴量が3個の場合のイメージを描いてみました。
(アヤメの特徴量が3次元の時)
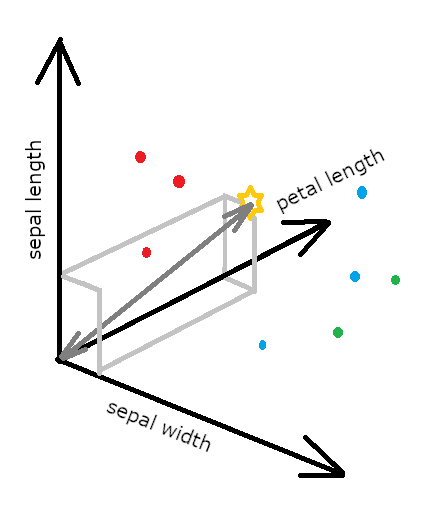
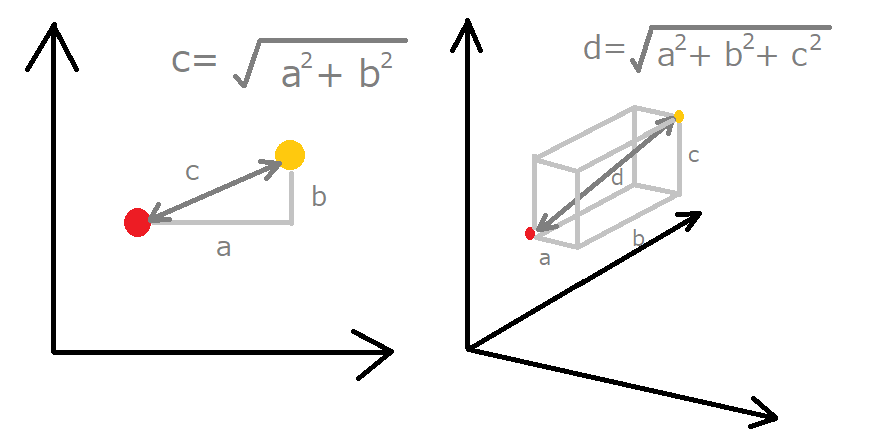
実際、アヤメのデータの特徴量は、4個あるので、4次元ということになるのですが、3次元以上は、数式などで見るしかできないので、とりあえずこんなイメージで距離を求めて一番近いものとして分類する、ということがわかりました。
実際には、「ユークリッド距離」というものの距離を求めて近い遠いを出しています。
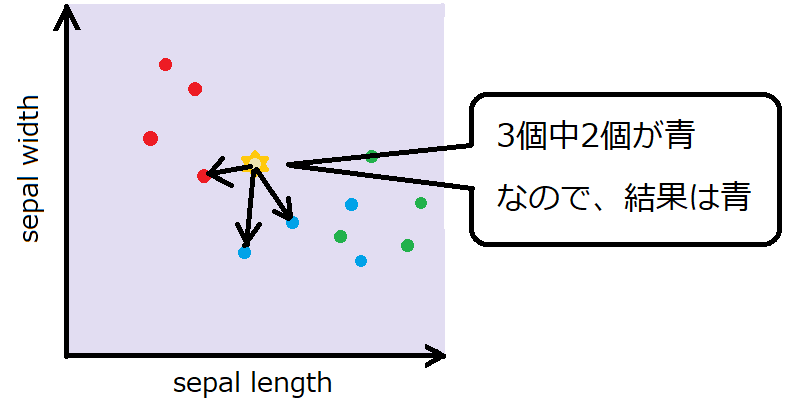
k最近傍法の「n_neighbors=1」について
n_neighborsが1の時は、距離が一番近いデータとして分類します。k最近傍法のkは、近傍のデータk個を比較するという意味でついています。
#k-最近傍法のオブジェクトの宣言
knc = KNeighborsClassifier(n_neighbors = 1)n_neighborsを3とすると、距離が3番目まで近いデータを比較してその3個のデータの多数決で分類を決定します。
基本的に、kの値が1と少ないほど、境界線が複雑に入り組んだものになります。
プログラムで検証
アヤメのデータのn-neighborsを3にしてみます。
from sklearn.datasets import load_iris
from sklearn.model_selection import train_test_split
#k-最近傍法のimport
from sklearn.neighbors import KNeighborsClassifier
import numpy as np
import pandas as pd
panda_box = load_iris()
X = panda_box.data
y = panda_box.target
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size = 0.5, stratify=y)
#k-最近傍法のオブジェクトの宣言
knc = KNeighborsClassifier(n_neighbors = 3)
#10回の評価
result = np.zeros(10)
for i in range(10):
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size = 0.5, stratify=y)
knc.fit(X_train, y_train)
result[i] = knc.score(X_test, y_test)
#numpyの表示を小数点2桁までに変更
np.set_printoptions(precision=2)
print("10回の結果を表示")
print(result)
print("10回の平均的な正解確率")
print("{:.2f}".format(result.sum()/10))今回は結果がそんなに変わりませんでした・・・
10回の結果を表示
[0.96 0.93 0.97 0.92 0.95 0.96 0.96 0.96 0.99 0.92]
10回の平均的な正解確率
0.95何回か試したところ、n_neighbor=9あたりが一番正答率が高そうです。10回を平均をさらに何回か試しても、平均して97くらいを維持していました。
まとめ:複雑な数学を知らなくても機械学習できる
scikit-learnを知ることで、複雑な数式を知らなくても、何をしているのか、概念的な部分を押さえておけば、機械学習のアルゴリズムを問題に対して最適にチューニングをしていくことができます。
まずは、いろいろプログラムで試してみて、数式などの知識も増やしていけたらいいなと考えています。