
アヤメのデータ構造が理解できて、どんなふうにデータが散らばっているもわかったよ。機械学習アルゴリズムでデータの分類をしてみようかな。
全部のデータを学習に使っちゃだめだよ。データの分け方を理解する必要があるね。
こんな人の役に立つかも
・機械学習プログラミングを勉強している人
・scikit-learnのtrain_test_split関数の使い方を知りたい
・機械学習のデータの分割について知りたい。
アヤメのデータを分割しよう
データは2つに分割する

機械学習のアルゴリズムにもっているデータをすべて学習させてしまうと、学習後のテストができませんので、「訓練データ」と「テストデータ」に分けます。
訓練データとテストデータに分割する必要性
例えば、テストに臨むときに、過去問題で勉強をしたとします。
本番が、過去問題と全く同じ問題のみで構成されているテストだったら・・・すべての答えがわかってしまいますよね?このような状態になってしまうと、学習させたはいいが・・・どれくらい使えるんだろう、ということが検証できないことになってしまいます。
原付のテストみたいに問題の数が限られてれば、問題の答え覚えればOKだけど、そんなシンプルな課題に機械学習使う必要ないな・・・
ホールドアウトという方法
訓練用データとテスト用データに分割して、機械学習アルゴリズムに学習させる、有効性を検証するという方法をホールドアウトというらしいです。
今後、機械学習の開発とかし始めたら、仲間とかに「ホールドアウトでいこう(`・ω・´)キリッ」と言いたいので、覚えておきましょう。
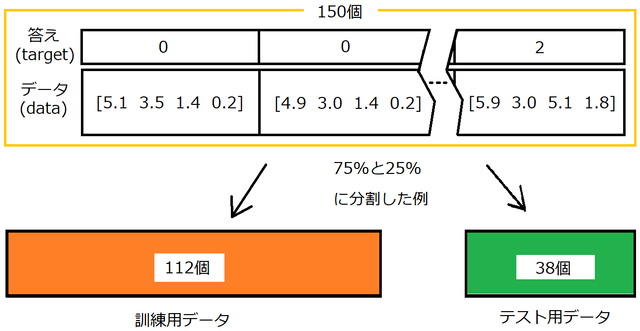
訓練用データでプログラムに学習をさせます。そうすることで、テスト用データはプログラムにとって未知のデータとなるので、学習した結果を検証することができるという具合です。
データをプログラミングで分割
scikit-learnライブラリには、訓練データとテストデータに分割する便利な機能があります。
train_test_split関数でデータを分割しよう
importでは、train_test_splitを使えるようにする必要があります。
from sklearn.datasets import load_iris
#train_test_splitを使えるようにimportする
from sklearn.model_selection import train_test_split
import numpy as np
import matplotlib.pyplot as plt
import pandas as pd
import seaborn as sns
#アヤメデータを読み込む
panda_box = load_iris()
#「"data"」と「"target"」のデータをXとyという変数に読み込む
X = panda_box.data
y = panda_box.targetXとyという変数名は、自由に命名することができます。機械学習のプログラミングでは、特徴量のデータを「大文字のX」、答えのラベルデータを「小文字のy」で表現することが一般的らしいです。ですので、アヤメの特徴量データ(”data”)をXに入れて、答えのラベルデータ(“target”)をyという変数に入れることにしました。
#訓練データとテストデータへの分割
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size = 0.5)
#データ個数の確認
print("X_train", X_train.shape)
print("X_test", X_test.shape)
print("y_train", y_train.shape)
print("y_test", y_test.shape)train_test_splitは、下の図のように、Xとyを次のように分割してくれます。また、アヤメのデータは「setosa」「verginica」「versicolor」という順番に並んでいたので、いい感じにデータをシャッフルして分割してくれます。
今回は、Xのトレーニング用をX_train、テスト用をX_test、yのトレーニング用をy_train、yのテスト用をy_testという名前の変数に入れます。
分割の割合は、test_size=のあとに「0.5」とすると半分の割合でデータが分割されます。この指定を省く場合、訓練データを75%、テストデータを25%というデータの割合で分割します。

そのあとのprint文で、以下のようにデータ個数を確認しています。それぞれ訓練用75個、テスト用75個のデータに分割されることがわかりました。
X_train (75, 4)
X_test (75, 4)
y_train (75,)
y_test (75,)まとめ:学習データはホールドアウト法で分割しよう
学習データを分割一番基本的な方法がホールドアウトという方法で、scikit-learnのtrain_test_split関数を利用することで、簡単にデータを訓練用とテスト用に分割することができました。
確かに、scikit-learnは、機械学習のプログラミングをとても楽にしてくれていることが、改めて理解できました。
ここまでで、機械学習もうできるんじゃないかな~と思っていたのですが、分割されたデータの内容についてもう少し勉強が必要です。次回は、分割されたデータの割合についてもう少し掘り下げていきます。
次の記事はこちらです。

今回のプログラムの全体
from sklearn.datasets import load_iris
#train_test_splitを使えるようにimportする
from sklearn.model_selection import train_test_split
import numpy as np
import matplotlib.pyplot as plt
import pandas as pd
import seaborn as sns
#アヤメデータを読み込む
panda_box = load_iris()
#「"data"」と「"target"」のデータをXとyという変数に読み込む
X = panda_box.data
y = panda_box.target
#訓練データとテストデータへの分割
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size = 0.5)
#データ個数の確認
print("X_train", X_train.shape)
print("X_test", X_test.shape)
print("y_train", y_train.shape)
print("y_test", y_test.shape)