
前回、ランダムフォレストでDigitを分類したけれど、結構いい感じのスコアが出ました。
PCAで特徴量を抽出したらもっとスコアは上がるかな??
前回、ランダムフォレストでDigitデータを分類してみました。サポートベクターマシンほどではなかったのですが、結構良いスコアとなりました。サポートベクターマシンのときは、データにPCAをすることで、スコアの向上が見られました。同様に、ランダムフォレストでもPCAしたデータでどのようになるか試してみたいと思います。
前回のランダムフォレストでDitigデータを分類した記事はこちらをご参考ください。

サポートベクターマシンでDigitデータを分類した記事はこちらをご参考ください。

こんな人の役に立つかも
・機械学習プログラミングを勉強している人
・scikit-learnでPCAをプログラミングしたい人
・scikit-learnでランダムフォレストのプログラミングがしたい人
PCAをしてランダムフォレストで分類
import~データの読み込み、データの分割まで
from sklearn import datasets
from sklearn.model_selection import train_test_split
from sklearn.model_selection import cross_val_score
import numpy as np
#結果評価関連
from sklearn.metrics import confusion_matrix
from sklearn.metrics import classification_report
panda_box = datasets.load_digits()
X = panda_box.data
y = panda_box.target
#訓練データとテストデータに分割
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size = 0.25, stratify=y, random_state=0)次にPCAを行います。PCAを行ったら、抽出した主成分特徴量の寄与率を見てみます。
DigitデータをPCA
PCAについては、こちらの記事もご参考ください。

import matplotlib.pyplot as plt
#PCA
from sklearn.decomposition import PCA
#白色化
pca = PCA()
pca.fit(X_train)
X_train_pca = pca.transform(X_train)
X_test_pca = pca.transform(X_test)
#寄与率を表示
plt.plot(pca.explained_variance_ratio_)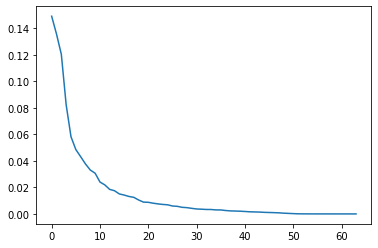
ここは、サポートベクターマシンの時と同じで、大体30主成分目までがデータに影響していそうな雰囲気です。
パラメータ調整
PCAで特徴量を抽出したDigitデータに対して、パラメータ「n_estimators」の変化でどのようにスコアが変化するかを見ていきます。
また、PCAで抽出した特徴量は、どこまで次元削減できるかも、検討します。
今回は、
①「n_estimators」の変化で一番よい設定を検討
②PCA特徴量の削減
という流れで調整しました。
①パラメータn_estimatorsを変化させてみる
まずは、「n_estimators」パラメータの変化でどのようにスコアが変化するかを可視化します。このプログラムは、3分割交差検証も行っているため、実行するのにGoogle Colabo環境で約3、4分程度かかります^^;
from sklearn.ensemble import RandomForestClassifier
train_dat_array = []
for i in range(50, 150):
#交差検証へのスコア
clf = RandomForestClassifier(n_estimators=i, random_state=0)
score = cross_val_score(clf, X_train_pca, y_train, cv=3)
train_dat_array.append(np.mean(score))3分割交差検証のスコアになります。
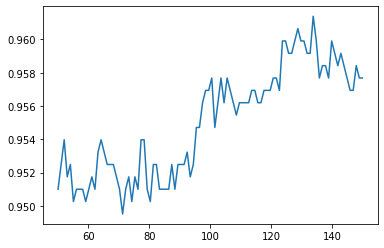
全体的に、n_estimatorsが120以降が良い雰囲気です。130前後がスコアのピークとなっていますね。今回は、130を利用することにします。
※Google Colaboで、再接続したりすると実行毎に結果が違ってきます。
n_estimators=120としてテストデータスコアをだすと、96.22%でした。
clf = RandomForestClassifier(n_estimators=130, random_state=0).fit(X_train_pca, y_train)
print("{:.4f}" .format(clf.score(X_test_pca, y_test)))0.9644②PCAの主成分特徴量の削減
次に、PCAで抽出した主成分特徴量がどこまで削減できるかを検討してみます。
from sklearn.metrics import accuracy_score
clf = RandomForestClassifier(n_estimators=120, random_state=0)
score_array = []
for i in range(10, 50):
#テストデータ評価
clf.fit(X_train_pca[:, 0:i+1], y_train)
predict = clf.predict(X_test_pca[:, 0:i+1])
score_array.append(accuracy_score(y_test,predict))
#テストデータに対するスコアをプロット
plt.plot(np.linspace(10, 50, 40), score_array)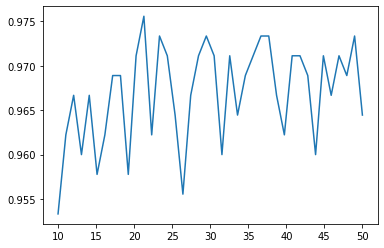
特徴量が22くらいがピークです。今回は、22個の特徴量を選択します。
clf.fit(X_train_pca[:, 0:22], y_train)
print("{:.4f}" .format(clf.score(X_test_pca[:, 0:22], y_test)))0.9756こうして、テストデータへのスコアが97.56%となりました。
まとめ
デフォルトのランダムフォレストに、何もしていないDigitデータを入れたときのスコアが97.33%でしたので、頑張って調整した割には、あまりスコアが上がっていないような感覚です^^;
ランダムフォレストは、ランダム性が存在するため、一概にこのパラメータが最強ということは出来なさそうなのです。
Digitデータの場合は、サポートベクターマシンのほうが良いのかな、と思いました。
勾配ブースティングもどうなるか気になってきました。