
k最近傍法でかなり良い結果が出ましたが、サポートベクターマシンも試してみたいと思います。
いろいろ試してみるのも大事だね!
数字の文字画像分類のDigitをサポートベクターマシンで行ってみました。単純にアルゴリズムを訓練して、スコアを確認するだけだと面白くなかったので、PCAをしたりいろいろ試してみました。何となく機械学習アルゴリズムのチューニングというものがわかってきたような気もするこの頃です。
前回のk最近傍法でのDigitの分類はこちらの記事もご参考ください。

こんな人の役に立つかも
・機械学習プログラミングを勉強している人
・サポートベクターマシンでDigitデータセットを分類したい人
・scikit-learnでサポートベクターマシンの分類をプログラミングしたい人
Digitデータをサポートベクターマシンで分類
まずはimportとデータ読み込み
全体に共通するimport~Digitデータの読み込み、train_test_splitで訓練データとテストデータへの分割を行います。
from sklearn import datasets
from sklearn.model_selection import train_test_split
from sklearn.model_selection import cross_val_score
import numpy as np
#結果評価関連
from sklearn.metrics import confusion_matrix
from sklearn.metrics import classification_report
panda_box = datasets.load_digits()
X = panda_box.data
y = panda_box.target
#訓練データとテストデータに分割
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size = 0.25, stratify=y, random_state=0)まずは普通にやってみる
次に、サポートベクターマシンを作成して、交差検証してみます。
サポートベクターマシンについてはこちらの記事もご参考ください。

from sklearn import svm
#サポートベクターマシン
clf = svm.SVC(kernel='rbf')
#clf = svm.SVC(kernel='linear')
#交差検証
score = cross_val_score(clf, X_train, y_train, cv=3)
#結果の表示
print("交差検証の結果")
print(score)
print("交差検証の平均")
print("{:.4f}".format(np.mean(score)))
#テストデータ評価
clf.fit(X_train, y_train)
predict = clf.predict(X_test)
print("==ConfusionMatrix==")
print(confusion_matrix(y_test, predict))
print("==ClassificationReport==")
print(classification_report(y_test, predict, digits=4))交差検証の結果
[0.99331849 0.9844098 0.98218263]
交差検証の平均
0.9866
==ConfusionMatrix==
[[45 0 0 0 0 0 0 0 0 0]
[ 0 46 0 0 0 0 0 0 0 0]
[ 0 0 44 0 0 0 0 0 0 0]
[ 0 0 0 45 0 0 0 1 0 0]
[ 0 0 0 0 43 0 0 0 2 0]
[ 0 0 0 0 0 46 0 0 0 0]
[ 0 0 0 0 0 0 45 0 0 0]
[ 0 0 0 0 0 0 0 45 0 0]
[ 0 2 0 0 0 0 0 0 41 0]
[ 0 0 0 0 0 1 0 0 0 44]]
==ClassificationReport==
precision recall f1-score support
0 1.0000 1.0000 1.0000 45
1 0.9583 1.0000 0.9787 46
2 1.0000 1.0000 1.0000 44
3 1.0000 0.9783 0.9890 46
4 1.0000 0.9556 0.9773 45
5 0.9787 1.0000 0.9892 46
6 1.0000 1.0000 1.0000 45
7 0.9783 1.0000 0.9890 45
8 0.9535 0.9535 0.9535 43
9 1.0000 0.9778 0.9888 45
accuracy 0.9867 450
macro avg 0.9869 0.9865 0.9866 450
weighted avg 0.9869 0.9867 0.9867 4503分割交差検証の結果、平均的に98.66%の正解率が出ました。何もチューニングしなくてこのスコア・・・さすがですね。
もうこれでいいんじゃないかな・・・
交差検証、ConfusionMatrixについてはこちらの記事もご参考ください。


ClassificationReportは、こちの記事の最後もご参考ください。

PCAでデータを抽出してみよう
何もしないのも悔しいので、PCA(主成分分析)をおこなって、特徴量から主成分抽出します。
PCAで抽出された新たな特徴量は、訓練データを「X_train_pca」の変数に、
テストデータを「X_test_pca」の変数に入れます。
※PCAで抽出された主成分をこの後、勝手に主成分特徴量とか言ってますが、これはPCAで変換された特徴量のことを言っています。
PCA(主成分分析)については、こちらの記事もご参考ください。

#PCA
from sklearn.decomposition import PCA
#デフォルト設定のPCA(白色化しないほうが精度が出ました)
pca = PCA()
pca.fit(X_train)
X_train_pca = pca.transform(X_train)
X_test_pca = pca.transform(X_test)
#寄与率
#print(pca.explained_variance_ratio_)
plt.plot(pca.explained_variance_ratio_)PCAから抽出された主成分特徴量の寄与率をmatplotlibでグラフ化してみます。PCAをすることで得られた主成分特徴量がどれくらいデータに影響しているかがわかります。
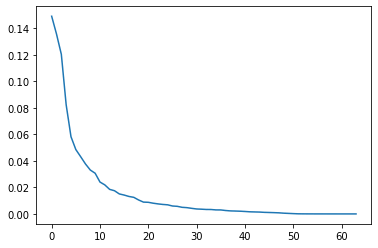
40個目くらいの主成分特徴量からあまりデータに影響がなさそうな感じだね。
とりあず、主成分特徴量30個分で良さそうなので、主成分特徴量30個でサポートベクターマシンを訓練させてみましょう。
「j」という変数に何個目までの主成分特徴量を利用するかを入力できるようになっています。
主成分としてPCAで抽出された特徴量は寄与率の大きい順番に並んでいるので、Pythonの列のスライス表記「X_train_pca[ : , 0:30]」のように記載することで寄与率の高い順番に主成分特徴量を利用できるので便利ですね。
#主成分特徴量の個数を指定する変数
j = 30
#交差検証
score = cross_val_score(clf, X_train_pca[:, 0:j], y_train, cv=3)
#結果の表示
print("交差検証の結果")
print(score)
print("交差検証の平均")
print("{:.4f}".format(np.mean(score)))
#テストデータ評価
clf.fit(X_train_pca[:, 0:j], y_train)
predict = clf.predict(X_test_pca[:, 0:j])
#print("==ConfusionMatrix==")
#print(confusion_matrix(y_test, predict))
print("==ClassificationReport==")
print(classification_report(y_test, predict, digits=4))ConfusionMatrixは特に今は見なかったので、コメントアウトしました^^;
交差検証の結果
[0.99554566 0.9844098 0.98218263]
交差検証の平均
0.9874
==ClassificationReport==
precision recall f1-score support
0 1.0000 1.0000 1.0000 45
1 1.0000 1.0000 1.0000 46
2 1.0000 1.0000 1.0000 44
3 1.0000 0.9783 0.9890 46
4 1.0000 0.9778 0.9888 45
5 1.0000 1.0000 1.0000 46
6 1.0000 1.0000 1.0000 45
7 0.9783 1.0000 0.9890 45
8 0.9773 1.0000 0.9885 43
9 1.0000 1.0000 1.0000 45
accuracy 0.9956 450
macro avg 0.9956 0.9956 0.9955 450
weighted avg 0.9957 0.9956 0.9956 45099.56%というテストデータへの結果が出ました、効果ありましたね。
PCAをして特徴量を30個に減らした方が、デフォルトのサポートベクターマシンに50個の特徴量を与えるよりも良いスコアとなりました。