
scikit-learnのアヤメデータは、特徴量が4つあるので、散布図を作ると6通りの組み合わせができてしまう。全部を確認するのは大変だな・・・
ペアプロットという方法で一度にすべての特徴量の組み合わせの散布図が作成できるよ
前回の「scikit-learnのアヤメのデータを分析、散布図でデータを見る」の続きです。

今回は、ペアプロットを行うためのseaboneの使い方等が中心となります。
こんな人の役に立つかも
・seaboneライブラリを利用してペアプロットを行いたい。
・scikit-learnライブラリのアヤメのデータの分析方法が知りたい。
・Pythonのデータ分析の勉強がしたい。
ペアプロットでデータの概要をつかむ
今回作成する図は、下のようなものです。
ペアプロットをすることで、対角に表示されているグラフが特徴量のデータの個数の分布、その周りに、それぞれの特徴量の散布図が描かれます。
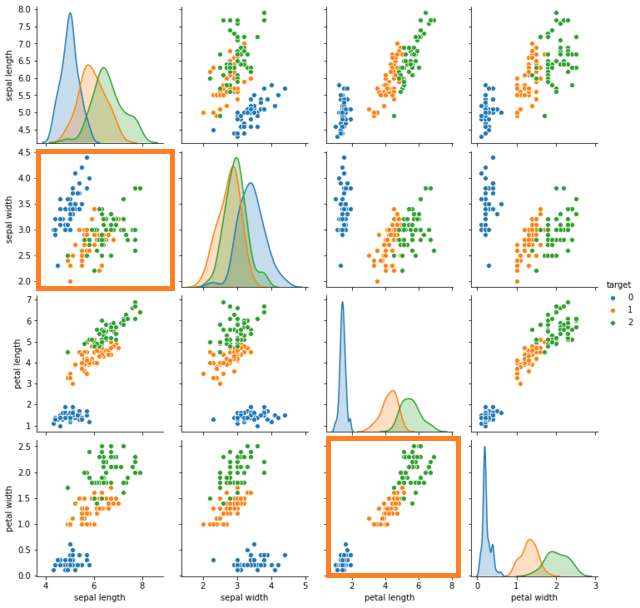
前回プロットした散布図以外にも、「setosa」のアヤメは他の種類と比較してかなり分離しているので、判断が簡単にできそうです。一方、「versicolor」と「verginica」は微妙にデータがかぶっていて、分離するには一苦労かかりそうですね。
ちなみに、左下の6個の散布図ですべての組み合わせとなります。右上の6個は軸が反対になっているだけです。
ペアプロットからわかること、ルールベースと機械学習
機械学習がなかったら、この図から、どのような条件にすればうまく分類ができるかを作成しなければいけませんでした。
例えば、一番シンプルなルールは、「petal width」が0.8より小さい場合は「setosa」という種類だ、という条件分岐をプログラムにさせていく感じです。
一方、機械学習は、これらのデータを学習させることで、ちょうど良い境界線を引いてくれますので、人間がひとつづつルールを作成するよりも、精度が高い分類ができそうです。
「verginica」と「versicolor」はどれも混ざっているところがあって分類が難しそう・・・
ペアプロットのプログラムを作成
まずは、ライブラリのimportから
まずは、以下のライブラリをimportします。前回の散布図のプログラムから、さらに1つ使うライブラリが増えました。seaboneというかっこいい名前のライブラリです。グラフをきれいに表示してくれます。
※seaboneは「as sns」と、変な略称になっていますが、アメリカのテレビドラマのキャラクターの名前(Samuel Norman Seaborn)からとられたそうで、この略称が一般的になってます。わかりにくい・・・snsの部分は好きな略称にできます。
from sklearn.datasets import load_iris
import matplotlib.pyplot as plt
import pandas as pd
import seaborn as sns
#panda_boxという名前の変数(自由な命名)にアヤメデータをロードする
panda_box = load_iris()pandasライブラリにも、ペアプロットをするための機能は準備されているのですが、seaboneライブラリを使うことでグラフの見やすさが格段にアップしましたので、今回はseaboneを利用します。
seaboneでグラフを書くためのデータを作成
seaboneでペアプロットを描くためには、データとその答えが一緒になったDataFrameという形のデータが必要になります。
いまは、「”data”」と「”target”」にデータが分かれているので、これを結合して次のようなデータを作成します。
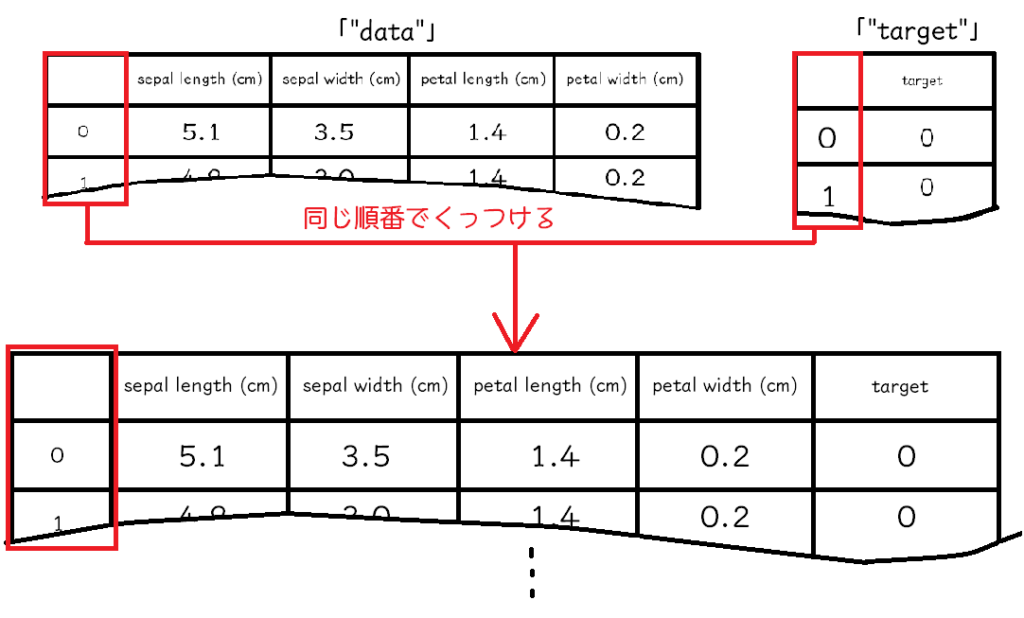
「”data”」をDataFrameに変換
iris_dataframe(命名は自由)という名前の変数にDataFrameの形に変化させた「”data”」を入れます。
#DataFrameにデータ変換してiris_dataframe変数に入れる。
iris_dataframe = pd.DataFrame(panda_box.data)
#iris_dataframe変数を表示
print(iris_dataframe)以下のように、iris_dataframe変数をprint文で表示させると、dataが入っています。4列のデータの表となっています。ここでは、PandasのDataFrameという形にデータを変更することが大切です。
0 1 2 3
0 5.1 3.5 1.4 0.2
1 4.9 3.0 1.4 0.2
2 4.7 3.2 1.3 0.2
3 4.6 3.1 1.5 0.2
4 5.0 3.6 1.4 0.2
.. ... ... ... ...
145 6.7 3.0 5.2 2.3
146 6.3 2.5 5.0 1.9
147 6.5 3.0 5.2 2.0
148 6.2 3.4 5.4 2.3
149 5.9 3.0 5.1 1.8
[150 rows x 4 columns]「”target”」をDataFrameに変換
先ほどの「”data”」と同様に、iris_target_dataframeという名前(命名自由)の変数にDataFrameの形にした「”target”」データを入れます。
iris_target_dataframe = pd.DataFrame(panda_box.target)
print(iris_target_dataframe)次のように、1列だけの表になります。
0
0 0
1 0
2 0
3 0
4 0
.. ..
145 2
146 2
147 2
148 2
149 2「”data”」と「”target”」を結合して一つのデータの表に
#表の結合
md = pd.merge(iris_dataframe, iris_target_dataframe, left_index=True, right_index=True)
#結合した表の列名をつける。
md.columns = ['sepal length', 'sepal width', 'petal length', 'petal width', 'target']
print(md)mdという変数(命名自由)に、先ほどの「iris_dataframe」と「iris_target_dataframe」の結合したデータを入れています。pd.merge()という関数で結合ができます。
pdはimportしたときのPandasライブラリの略称ですね。「.」をつなげると、ライブラリに登録されている機能にアクセスできます。今回は、mergeという表と表を合体させる機能を利用します。
mergeは、(左の表、右の表、左の表のインデックス、右の表のインデックス)と指定します。
「左の表のインデックス」は、最初から表についているデータの番号をとしたいので、「left_index = True」とします。右の表も同じようにデータの番号をインデックスにしたいので、「right_index=True」とします。インデックスは結合するときにこの同じインデックス同士の行を結合するため、必要になります。
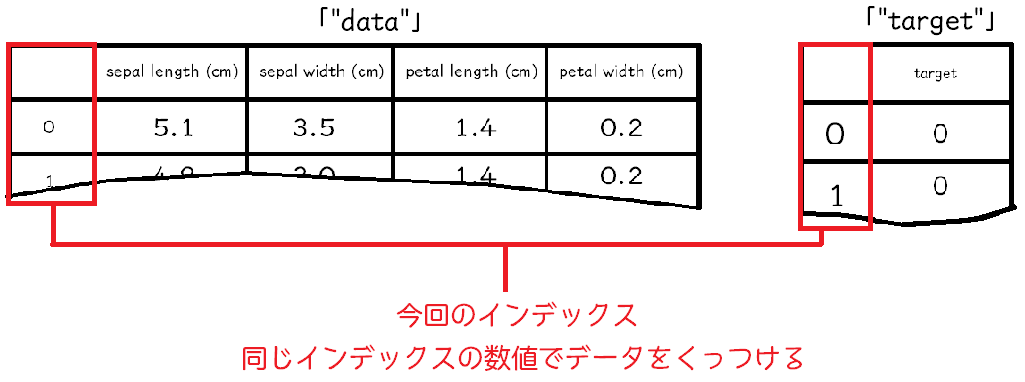
※Pandasは、このように簡単に表形式のデータを操作することができるメリットがあるため、広く使われます。
printの結果は、下のように、1行に5つのデータが入っていて、列名もちゃんとcolumnで指定したものになっています。
sepal length sepal width petal length petal width target
0 5.1 3.5 1.4 0.2 0
1 4.9 3.0 1.4 0.2 0
2 4.7 3.2 1.3 0.2 0
3 4.6 3.1 1.5 0.2 0
4 5.0 3.6 1.4 0.2 0
.. ... ... ... ... ...
145 6.7 3.0 5.2 2.3 2
146 6.3 2.5 5.0 1.9 2
147 6.5 3.0 5.2 2.0 2
148 6.2 3.4 5.4 2.3 2
149 5.9 3.0 5.1 1.8 2seaboneでペアプロット
ここでやっとデータがそろいましたので、ペアプロットの関数でグラフを表示させます。
#図の作成と表示、表示までに数秒の時間がかかります。
sns.pairplot(md, hue="target")seaboneも最初のimportのときにsnsという省略名を付けました。snsに「.」をつけて、「pairplot」というペアプロットができる機能にアクセスします。
pairplotには、(DataFrameの形のデータ、hue=”色付けする列”)を指定します。
色付けする「hue」には、「”target”」列の0と1と2を使いたいので、”target”としています。このようにして、0と1と2という数字でデータが色分けされるようになります。
この色分けをしたくてseaboneを使いました。
まとめ:Pandasに慣れる必要があります
データを利用するためには、Pythonでよく使われるPandasというデータの加工をするライブラリを使いこなせると良いことがわかりました。今回は、データの結合などを行いましたが、自分でデータを収集したりし始めると、Pandasでのデータ加工などは必須になりそうです。
次は、アヤメのデータを訓練データとテストデータに分割することを学びました。

今回の記事のプログラム全体
from sklearn.datasets import load_iris
import matplotlib.pyplot as plt
import pandas as pd
import seaborn as sns
#panda_boxという名前の変数(自由な命名)にアヤメデータをロードする
panda_box = load_iris()
#DataFrameにデータ変換してiris_dataframe変数に入れる。
iris_dataframe = pd.DataFrame(panda_box.data)
#iris_dataframe変数を表示
print(iris_dataframe)
iris_target_dataframe = pd.DataFrame(panda_box.target)
print(iris_target_dataframe)
#表の結合
md = pd.merge(iris_dataframe, iris_target_dataframe, left_index=True, right_index=True)
#結合した表の列名をつける。
md.columns = ['sepal length', 'sepal width', 'petal length', 'petal width', 'target']
print(md)
#図の作成と表示、表示までに数秒の時間がかかります。
sns.pairplot(md, hue="target")