
Pandasというライブラリとmatplotlibというライブラリでアヤメのデータを散布図にして視覚的にデータの散らばりがわかるようにしたよ。
散布図にすると直感的だよね。
機械学習プログラミングをするまでには、データを理解する必要がありました。データ分析をして、そのうえで、データを機械学習で処理するか否かを決める前判断が必要となります。今回は、Pandasというデータを扱うPythonのライブラリを利用し、散布図というものを作成してみました。
アヤメのデータを利用します。アヤメデータに関する概要はこちらの記事をご参照ください。

こんな人の役に立つかも
・機械学習プログラミングを勉強している人
・アヤメデータの散布図を描きたい人
・Pythonで機械学習プログラミングを勉強している人
散布図でデータを確認
散布図は、データがどれくらい散らばっているかを確認するためのグラフです。
今回は、下のような散布図を作成します。赤色が「setosa」、青色が「versicolor」、緑色が「virginica」とそれぞれのアヤメの種類を表しています。↓の図では「sepal width」と「sepal length」の長さでデータをプロット(データの点を打つこと)しています。
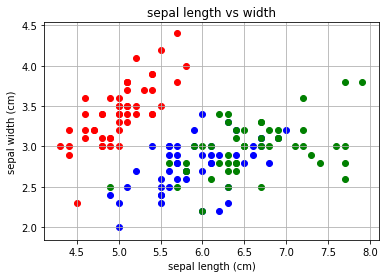
散布図にすると、どんなふうにデータが散らばっているかわかりやすい。
見やすいでしょ
散布図を描くためにプログラミングをする
Pandasとmatplotlibというライブラリを使えるように
Pandasは、Pythonのデータをエクセルの表のように扱える便利なライブラリです。PandasのDataFrameという変数にデータを入れることで、エクセルみたいにデータが扱えます。(が、結構慣れが必要です。)
matplotlibは、PandasのDataFrameのデータから、今回は散布図を描いてくれる便利なライブラリです。使い方はほぼ定型文です。
from sklearn.datasets import load_iris
import matplotlib.pyplot as plt
import pandas as pdPythonプログラムの最初にimportし、asとつけることでこれ以降のプログラムでPandasはpdと省略して記載、matplotlibはpltと省略して記載ができます。pltとかpdは好きな名前つけられますが、みんなplt、pdとしています。
変数にアヤメのデータを入れる
panda_box = load_iris()前回と同じように変数にアヤメのデータを入れます。
アヤメの種類毎にデータを分ける
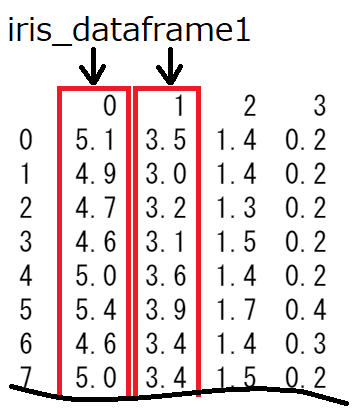
scikit-learnのアヤメのデータは、50番目まで「setosa」、51番目~100番目が「versicolor」、101番目~最後までが「virginica」という順番なので、50個づつのデータに分割します。このときに、50個づつPandasのDataFrameというデータの形にしています。
iris_dataframe1 = pd.DataFrame(panda_box.data[:50])
iris_dataframe2 = pd.DataFrame(panda_box.data[50:100])
iris_dataframe3 = pd.DataFrame(panda_box.data[100:150])
matplotlibで散布図を作成
plt.scatterで散布図を作成することができます。
今回は、iris_dataframe1[0]とiris_dataframe[1]というように、「sepal length」と「sepal width」の列の散布図を作成しています。
plt.scatter(iris_dataframe1[0], iris_dataframe1[1], c="red")
plt.scatter(iris_dataframe2[0], iris_dataframe2[1], c="blue")
plt.scatter(iris_dataframe3[0], iris_dataframe3[1], c="green")
#以下で散布図の見た目の設定をしています。
plt.title('sepal length vs width')
plt.xlabel('sepal length (cm)')
plt.ylabel('sepal width (cm)')
plt.grid(True)このプログラムを実行すると、最初の散布図が表示されます。
プログラム全体
先ほどの手順のプログラム全体です。以下をJupyterNotebookに貼り付けても動作します。(グラフの描画に数秒かかるかも)
#必要なPythonライブラリのimport
from sklearn.datasets import load_iris
import matplotlib.pyplot as plt
import pandas as pd
#変数にアヤメのデータを入れる
panda_box = load_iris()
#アヤメのデータをアヤメの種類毎に分ける
iris_dataframe1 = pd.DataFrame(panda_box.data[:50])
iris_dataframe2 = pd.DataFrame(panda_box.data[50:100])
iris_dataframe3 = pd.DataFrame(panda_box.data[100:150])
#matplotlibで散布図を描く
plt.scatter(iris_dataframe1[0], iris_dataframe1[1], c="red")
plt.scatter(iris_dataframe2[0], iris_dataframe2[1], c="blue")
plt.scatter(iris_dataframe3[0], iris_dataframe3[1], c="green")
#以下で散布図の見た目の設定をしています。
plt.title('sepal length vs width')
plt.xlabel('sepal length (cm)')
plt.ylabel('sepal width (cm)')
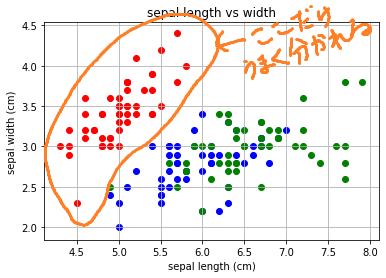
plt.grid(True)このプログラムは、「sepal length」と「sepal width」を比較しました。見てわかりますが、この散布図だと、「setosa」のデータはうまく分離しているように見えますが、それだけですね^^;
こんどは、「petal width」と「petal length」の散布図を描いてみました。
iris_dataframe1の[0]を[2]に、[1]を[3]に変更して、列を変えただけです。(iris_dataframe2、iris_dataframe3も同様)
#matplotlibで散布図を描く
plt.scatter(iris_dataframe1[2], iris_dataframe1[3], c="red")
plt.scatter(iris_dataframe2[2], iris_dataframe2[3], c="blue")
plt.scatter(iris_dataframe3[2], iris_dataframe3[3], c="green")
#以下で散布図の見た目の設定をしています。
plt.title('petal length vs width')
plt.xlabel('petal length (cm)')
plt.ylabel('petal width (cm)')
plt.grid(True)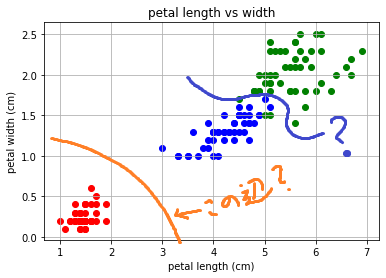
こっちのほうがうまく分離しています。手書きで書いた線みたいなものを算出すれば、データの境界線みたいなものがみつかりそうな雰囲気がありますね。
機械学習の「データあり学習」の「分類」はこのようなうまく分けられる境界線を割り出してくれるんだね。
ということで、縦軸と横軸にとる項目を変化させることでデータのばらつき具合がどのようになっているかを確認することができました。
この縦軸と横軸にとる項目のことを「特徴量」と呼びます。
特徴量の組み合わせは、
①sepal width (vs) sepal length
②sepal width (vs) petal width
③sepal width (vs) petal length
④sepal length (vs) petal width
⑤sepal length (vs) petal length
⑥petal length (vs) petal width
という組み合わせで散布図が作成できますね。これらの特徴量の組み合わせで散布図を描き、どのように分離したらうまく種類が分けられるかを考えればアヤメを種類ごとにうまく分類できるようになることがわかりました。
まとめ:まずは散布図でデータを確認しました
今回は、機械学習の機の字もなく散布図の描画をしました。しかし、少し見えてきたことは、この散布図の上にどのように線を引くか、という線の引き方を機械学習のアルゴリズムがやってくれそうなにおいもしてきました。
この散布図の特徴量の組み合わせすべてを一度に表示できるペアプロットという方法があるらしいので、そのあたりもできたらいいなと思います。
次は、沢山の散布図を同時に確認できるペアプロット という方法を学びました。
