
機械学習プログラミングの勉強をはじめて、まずはアヤメのデータの分類をしようとしてます。アヤメのデータはscikit-learnにすでに含まれているんだね。
アヤメのデータは、機械学習を始める際のいい素材だね。scikit-learnライブラリから呼び出してみるよ。
機械学習プログラミングで定番のアヤメのデータをいじっています。
今回は、scikit-learnライブラリでアヤメのデータを理解する部分を行いました。
こんな人の役に立つかも
・Pythonプログラミングが初めてでscikit-learnライブラリを使いたい人
・機械学習プログラミングを始めたい人
・scikit-learnライブラリでアヤメのデータを取得したい人
※私は現在、Anaconda環境のJupyterNotebookでプログラミングの学習をしています。

scikit-learnライブラリのアヤメのデータ
アヤメのデータで何をするのか?
機械学習で、たくさんのアヤメの「花びらとがく」の大きさのデータと、そのデータの「アヤメの種類」データを学習させます。
その結果、アヤメの「花びらとがく」の大きさのデータだけで、「このアヤメの種類はこれ」というように、アヤメの種類をプログラムに分類させよう、というチュートリアルです。
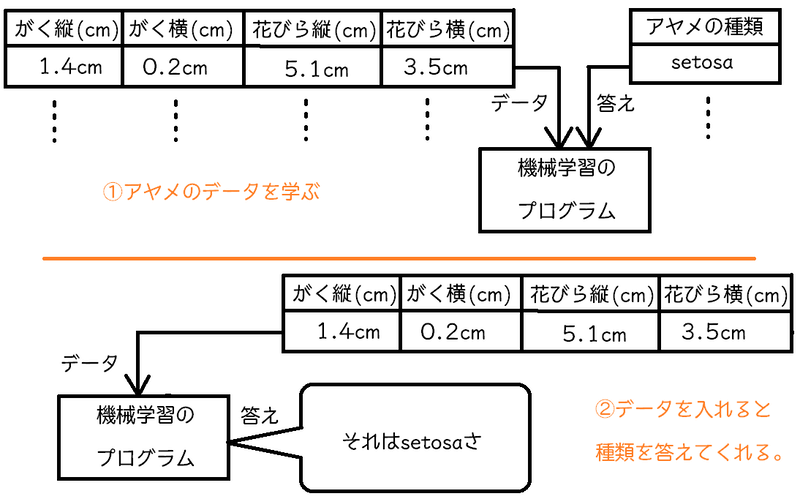
このアヤメの例題は、かなり基本的なものらしく、scikit-learnライブラリに組み込まれているとのことです。
機械学習のHelloWorld的ポジション? ハロポジですね。
アヤメのデータの構成を確認
scikit-learnライブラリには、アヤメのデータがあらかじめ組み込まれています。scikit-learnライブラリのload_iris関数を呼び出すと、アヤメのデータを取得することができます。
from sklearn.datasets import load_iris
panda_box = load_iris()scikit-learnライブラリを使うには、まずインポート(import)しないと使うことができません。1行目でscikit-learnライブラリからload_irisというアヤメのデータを呼び出す関数をインポートします。
2行目は、「panda_box」という名前の変数にload_iris()関数でアヤメのデータを入れています。変数は、データを入れるための箱になります。数値などのデータを一時的に保存しておくために変数という箱を作ります。
プログラムの「=」は、右(load_irisが持ってきたアヤメのデータ)のものを左(変数panda_box)に入れるという意味です。
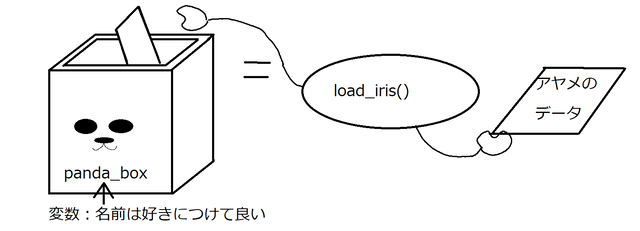
次に、print文で、変数に入っている値を見ることができます。print文で、アヤメのデータを見てみましょう。
print(panda_box)次のような結果が得られます。(省略形)
{'data': array([[5.1, 3.5, 1.4, 0.2],
[4.9, 3. , 1.4, 0.2],
[4.7, 3.2, 1.3, 0.2],
[4.6, 3.1, 1.5, 0.2],
[5. , 3.6, 1.4, 0.2],
[5.4, 3.9, 1.7, 0.4],
~~
'target': array([0, 0, 0, 0,
~~~
'DESCR': '
~~
'feature_names':
~~~データの全部を表示させるとよくわからないのですが、アヤメのデータは次の図ようになっています。
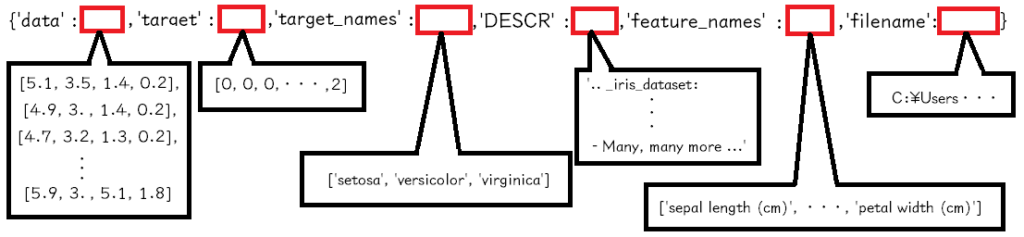
‘data’・・・150個のアヤメのデータ。1個のアヤメに対して4つのデータが存在します。
「sepal length (cm)’, ‘sepal width (cm)’, ‘petal length (cm)’, ‘petal width (cm)」
の順番でデータが並んでいます。(’feature_name’の順番)
とはいっても、私、アヤメの生態系がよくわからないので以下の事前知識が必要な模様です。内側の小さいほうが花びららしいです。緑の矢印のように横幅がwidth、赤の矢印のように縦の長さがlengthとなります。

そっちが花びらか・・・
‘target’・・・150個のアヤメの種類を表しています。0が、’setosa’という名前のアヤメ、 1が’versicolor’という種類のアヤメ、2が ‘virginica’という種類のアヤメとなります。この0がsetosaという対応付けはあとのデータの「’target_names’」で定義されています。
‘target’は、’data’に対する答えのデータとなります。’data’の1個目のデータ「5.1, 3.5, 1.4, 0.2」のpetalとsepalの長さのアヤメの種類は’target’の1個目のデータの「0」すなわち、「setosa」という種類のアヤメです。
‘target_names’と‘feature_names’は、先に出てきた通り、それぞれ’target’と’data’のデータの見出しを定義しているだけです。
また、‘DESCR’は「description」の略だと思われますが、このデータの説明書きが書かれています。
最後に、‘filename’は、アヤメのデータがインストールされている場所を示しています。
それぞれのデータを覗いてみる
次のようにprint文を記載することで、「”data”」のみ、「”target”」のみの内容を見ることができます。データの構成がどのようになっているか見てみます。
print(panda_box["data"])#または、↓
print(panda_box.data) 
「”data”」のデータは、上の図のように、1個目のデータの中にさらに4個のデータが存在する構成になっています。
print(panda_box["target"])#または、↓
print(panda_box.target) 「”target”」のデータは、数値データの羅列となります。
それ以外の「”DESCR”」なども見ることができます。
scikit-learnのデータ
アヤメのような機械学習を試すためのデータを「トイデータ」と呼ぶようです。アヤメのデータ以外にも、乳がんのデータや、ボストンの住宅価格データなど、さまざまなよく試しに使われるデータとして保存されています。
scikit-learnの「トイデータ」は基本的に
「.data」でそれぞれの特徴データにアクセスでき、「.target」でそれぞれの答えデータにアクセスできるように共通化されています。
まとめ:機械学習プログラミングは、データの理解が重要
scikit-learnのアヤメのデータは、「”data”」にアヤメの花びらデータが、「”target”」にそれぞれの「”data”」に対応するアヤメの種類が入っていることがわかりました。実際に学習に利用するには、まだいくつかの段階が必要ですが、今回のように用意されたデータではなく、自分でデータを準備するときにも、このようにデータを整理して保存しておく必要がありそうです。
しばらく、学習ではアヤメのデータの分類をやっていきたいと考えています。
次は、アヤメのデータを視覚化するために、散布図というものを作成しました。

GithubからオンラインのGoogle Colaboratory環境にて直接プログラムを確認することができます。

オンラインのPythonプログラミング環境、Google Colaboratoryについて知りたい方はこちらの記事もご参考ください。

