
勾配ブースティングマシンという名前がかっこいいやつを勉強しました。
アルゴリズムは見た目じゃなくて中身だよ。
決定木の流れで、ランダムフォレストと勉強してきましたが、今回は、最終進化のような、勾配ブースティングマシンというものを勉強しました。この勾配ブースティングマシンというアルゴリズムをベースにしたものは、かなり精度が出るみたいです。まずは、scikit-learnに実装されているもので試してみたいと思いました。
勾配ブースティングマシンは、決定木を応用したアルゴリズムです。決定木については、こちらの記事もご参考ください。

こんな人の役に立つかも
・機械学習プログラミングの勉強をしている人
・勾配ブースティングマシンについて知りたい人
・scikit-learnで勾配ブースティングマシンを勉強している人
勾配ブースティングマシンについて
勾配ブースティングマシンは、いくつかの決定木を組み合わせたアルゴリズムです。
「勾配ブースティング」の部分を英語で「GradientBoosthing」と言い、その後に分類ならClassifierがついて「GradientBoostingClassifier」のように使います。
回帰、分類の両方に利用できる、アンサンブル学習です。
アンサンブル学習とは
アンサンブル学習は、いくつもの基本的な学習アルゴリズムを組み合わせたものです。
勾配ブースティングは、決定木という基本的なアルゴリズムの組み合わせでできています。また、基本的なアルゴリズム(勾配ブースティングでいう決定木)を弱学習器といいます。
ランダムフォレストもアンサンブル学習です。
キングスラ〇ムのような感じのアルゴリズムかな。
なんだかすごそうだね。
scikit-learnの勾配ブースティングマシンで分類
scikit-learnライブラリでの勾配ブースティングマシンは、
分類用に「GradientBoostingClassifier」
回帰用に「GradientBoostingRegressor」
が準備されていますので、簡単に利用することができます。
乳がんデータの分類で威力偵察
import~乳がんデータの読み込みまでを行います。
from sklearn.datasets import load_breast_cancer
from sklearn.model_selection import train_test_split
from sklearn.ensemble import GradientBoostingClassifier
import matplotlib.pyplot as plt
import numpy as np
#乳がんデータ
panda_box = load_breast_cancer()
X = panda_box.data
y = panda_box.target
#訓練データとテストデータに分割
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size = 0.25, stratify=y, random_state=0)勾配ブースティングマシンの分類器を利用したいので、「GradientBoostingClassifier」を利用します。
#勾配ブースティングマシン
clf = GradientBoostingClassifier().fit(X_train,y_train)
print("訓練データへの精度")
print("{:.4f}" .format(clf.score(X_train, y_train)))
print("未知データへの精度")
print("{:.4f}" .format(clf.score(X_test, y_test)))訓練データへの精度
1.0000
未知データへの精度
0.9580訓練データへの精度が1ということは、過学習??
代表的なパラメータにlearning_rateがあるので、それを調整してみよう。
learning_rateは、デフォルト値で「0.1」です。この値を小さくすると、モデルの複雑さがなくなっていきますので、0.01とかにしたほうが訓練データに適合しすぎないのかもしれません。
次のプログラムで、「learning_rate」を「0.01~0.5」までの50回分を比較しました。
import matplotlib.pyplot as plt
import numpy as np
train_dat_array = []
test_dat_array = []
loop = 50
for i in range(loop):
clf = GradientBoostingClassifier(learning_rate=(i+1)*0.01).fit(X_train,y_train)
train_dat_array.append(clf.score(X_train, y_train))
test_dat_array.append(clf.score(X_test, y_test))
#グラフの描画
X_axis = np.linspace(0.01,loop*0.01,loop)
plt.plot(X_axis, train_dat_array)
plt.plot(X_axis, test_dat_array)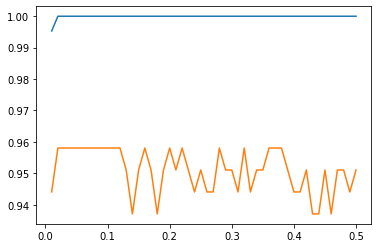
訓練データへの精度はずっと1なので、テストデータへの精度が良い、0.02当りを選択するのが良いのかもしれません。