
ConfusionMatrixを勉強したけど、ほんと混乱したよ。さらに、そこから「Precision(適合率)」と「Recall(再現率)」というものも勉強したよ。
PrecisionとRecallを見ることでより良いモデルが作れそうだね。
ConfusionMatrixを勉強しましたが、ConfusionMatrix自体は予測値の正解と不正解の内訳を表示するただの表にとどまっています。この数値をもとに分析するには何かしらの計算で求められる数値を改善したり、そういったアプローチが必要だと思います。そこで出てくる「適合率」と「再現率」というものを勉強しました。
ConfusionMatrixについてはこちらの記事もご参考ください。

こんな人の役に立つかも
・機械学習プログラミングを勉強している人
・機械学習の適合率、再現率を勉強している人
・scikit-learnで適合率、再現率を計算したい人
PrecisionとRecall
Precision(適合率)
「Precision」は日本語で「適合率」とかよんだりするようです。直訳すると精度なんですが、予測値に対する正解率の割合みたいなイメージで「予測値」がどれだけ正解しているかを示す割合になります。
前回の表で見てみると、

前回の乳がんデータ分類で、アルゴリズムが「1」と予測した答えのうち、正解したものは88個でした。「1と予測したデータ全体」は「7+88=95個」あるので、その割合、0.9263…が答えデータ「1」に対するPrecisionとなります。
同様に、予測した「0」にも同じ計算を行うことで、Precisionを求めることができます。
Recall(再現率)
再現率は英語で「Recall」と呼びます。今度は、教師の答えデータに対してどれだけ予測値が正解しているか、という数値になります。これは予測値がどれだけ再現できているか、という意味になると思います。
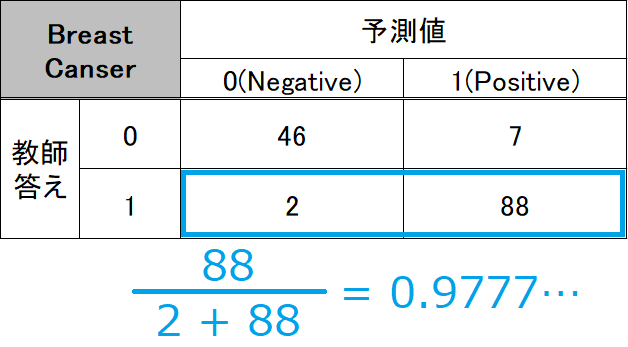
こちらも同様に、教師答え「1」に対するRecallも計算できます。
プログラムで計算してみる
import~乳がんデータを読み込み、ロジスティック回帰を作成しています。
#ホールドアウトのimport
from sklearn.model_selection import train_test_split,cross_val_score
#乳がんデータ
from sklearn.datasets import load_breast_cancer
#ロジスティック回帰
from sklearn.linear_model import LogisticRegression
import numpy as np
panda_box = load_breast_cancer()
X = panda_box.data
y = panda_box.target
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size = 0.25, stratify=y)
#ロジスティック回帰
cls = LogisticRegression(max_iter=10000)
#訓練~テスト
cls.fit(X_train,y_train)まずは単純な正解率の違う出し方
今までは、cls.scoreとすることで、正解率を算出できました。
print("訓練データの評価")
print("{:.4f}".format(cls.score(X_train, y_train)))
print("テストデータの評価")
print("{:.4f}".format(cls.score(X_test, y_test)))訓練データの評価
0.9577
テストデータの評価
0.9510次のようにすることで、同じように正解率を出すことができます。
#accyuracy_scoreをimport
from sklearn.metrics import accuracy_score
#単純な正解率を算出
#訓練データに対する正解率
predict = cls.predict(X_train)
print("{:.4f}" .format(accuracy_score(y_train, predict)))
#テストデータに対する正解率
predict = cls.predict(X_test)
print("{:.4f}" .format(accuracy_score(y_test, predict)))0.9577
0.9510accuracy_scoreは、アルゴリズムのscoreと同じ結果が得られます。データを準備する部分が長いのでscoreを使うより行数が増えてしましますが、scikit-learnのアルゴリズムでなくても、教師の答えデータとアルゴリズムの予測データがあるは正解率が出せますので、scikit-learn以外のアルゴリズムを利用した時などでも利用できます。
PrecisionとRecallを出す
sckearnのmetricsから、precision_scoreとrecall_scoreを読み込みます。
pos_labelというパラメータで、どの答えに対してPrecisionとRecallを出すのかを指定することができます。デフォルトでは1に設定してありますが、ここはパラメータで明記しておいたほうがわかりやすいと思います。
from sklearn.metrics import precision_score, recall_score
print("Precision")
print("1に対するPrecision")
print("{:.4f}" .format(precision_score(y_test, predict, pos_label=1)))
print("0に対するPrecision")
print("{:.4f}" .format(precision_score(y_test, predict, pos_label=0)))
print("Recall")
print("1に対するRecall")
print("{:.4f}" .format(recall_score(y_test, predict, pos_label=1)))
print("0に対するRecall")
print("{:.4f}" .format(recall_score(y_test, predict, pos_label=1)))Precision
1に対するPrecision
0.9462
0に対するPrecision
0.9600
Recall
1に対するRecall
0.9778
0に対するRecall
0.9057全部便利に算出する
ちなみに、今までやったそれぞれの答えに対するPrecisionやRecallを一括で出してくれるものが、classification_reportです。
from sklearn.metrics import classification_report
print(classification_report(y_test, predict)) precision recall f1-score support
0 0.96 0.91 0.93 53
1 0.95 0.98 0.96 90
accuracy 0.95 143
macro avg 0.95 0.94 0.95 143
weighted avg 0.95 0.95 0.95 143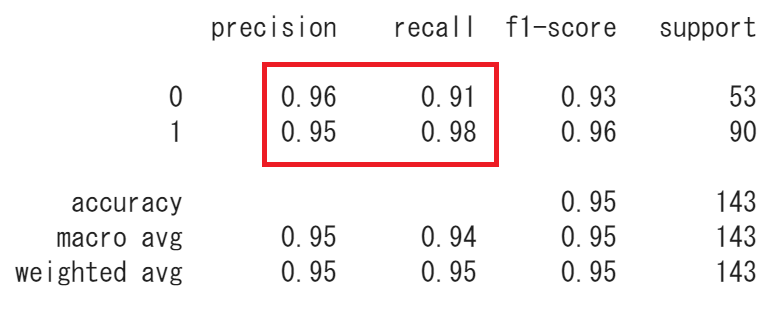
このように一括で先ほどの数値を算出することができました。
f1 scoreは、調和平均といって、パーセントを平均する数値らしいです。supportはそれぞれのデータの個数を表示しています。
とりあえずclassification_reportしておけば全部の値が見られるね。