
ランダムフォレストでもDigitデータを分類してみました。
いろいろな分類器で試してみると新しい発見があるかな。
前回は、サポートベクターマシンでテストデータに対して99.5%というかなりのスコアを出すことができました。scikit-learnのアルゴリズムの選択方法のをもとにいろいろ試しましたが、サポートベクターマシンと同じ位置に、アンサンブル手法(EnsembleClassifier)がありましたので、ランダムフォレストも試してみることにしました。
サポートベクターマシン(SVC)や、k最近傍法の結果等についてはこちらの記事もご参考ください。
k最近傍法

サポートベクターマシン

こんな人の役に立つかも
・機械学習プログラミングを勉強している人
・Digitデータの分類をしたい人
・scikit-learnのランダムフォレストのプログラミングをしている人
ランダムフォレストで分類
まずは普通にランダムフォレストにデータを入れてそのまま確認してみます。
import~データ読み込み、分割部分
各種ライブラリの読み込み~データ読み込み、データ分割までを行います。
from sklearn import datasets
from sklearn.model_selection import train_test_split
from sklearn.model_selection import cross_val_score
import numpy as np
#結果評価関連
from sklearn.metrics import confusion_matrix
from sklearn.metrics import classification_report
panda_box = datasets.load_digits()
X = panda_box.data
y = panda_box.target
#訓練データとテストデータに分割
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size = 0.25, stratify=y, random_state=0)ランダムフォレストで分類
次に、ランダムフォレストを作成して、交差検証、訓練、テストデータへの評価を行います。
from sklearn.ensemble import RandomForestClassifier
#ランダムフォレスト
clf = RandomForestClassifier()
#交差検証
score = cross_val_score(clf, X_train, y_train, cv=3)
#結果の表示
print("交差検証の結果")
print(score)
print("交差検証の平均")
print("{:.4f}".format(np.mean(score)))
#テストデータ評価
clf.fit(X_train, y_train)
predict = clf.predict(X_test)
print("==ConfusionMatrix==")
print(confusion_matrix(y_test, predict))
print("==ClassificationReport==")
print(classification_report(y_test, predict, digits=4))交差検証の結果
[0.96659243 0.97550111 0.9688196 ]
交差検証の平均
0.9703
==ConfusionMatrix==
[[44 0 0 0 1 0 0 0 0 0]
[ 0 46 0 0 0 0 0 0 0 0]
[ 0 0 44 0 0 0 0 0 0 0]
[ 0 0 0 44 0 0 0 0 2 0]
[ 0 0 0 0 43 0 0 2 0 0]
[ 0 0 0 0 0 45 0 0 0 1]
[ 0 1 0 0 0 0 44 0 0 0]
[ 0 0 0 0 0 0 0 45 0 0]
[ 0 2 0 1 0 0 0 0 40 0]
[ 0 0 0 1 0 1 0 0 0 43]]
==ClassificationReport==
precision recall f1-score support
0 1.0000 0.9778 0.9888 45
1 0.9388 1.0000 0.9684 46
2 1.0000 1.0000 1.0000 44
3 0.9565 0.9565 0.9565 46
4 0.9773 0.9556 0.9663 45
5 0.9783 0.9783 0.9783 46
6 1.0000 0.9778 0.9888 45
7 0.9574 1.0000 0.9783 45
8 0.9524 0.9302 0.9412 43
9 0.9773 0.9556 0.9663 45
accuracy 0.9733 450
macro avg 0.9738 0.9732 0.9733 450
weighted avg 0.9737 0.9733 0.9733 450なにもしていない状態で、97.33%というスコアが出ました。
※この時点で、パラメータチューニングをしていないので、パラメータチューニング用途がメインの交差検証は、意味があまりないと思う点はご了承くださいm__m
サポートベクターマシンほどではないけれど、かなり良いスコアです。
このスコアを出したときのランダムフォレストのパラメータ「n_estimators」を確認してみます。このように、scikit-learnでは、アルゴリズムのパラメータを確認することができます。
print(clf.n_estimators)100「n_estimators」のパラメータが100ということでしたので、この100を変化させることで、どのようなスコアとなるかを試してみます。
パラメータを変化させてスコアを見る
for文で、「n_estimators」が50~149のときの交差検証をしたときの「交差検証結果の平均スコア」をグラフにしてみます。
ちなみに、このプログラムの実行にはGoogle Colabo環境で約2分程度かかりました。
import matplotlib.pyplot as plt
import numpy as np
train_dat_array = []
for i in range(50, 150):
#交差検証へのスコア
clf = RandomForestClassifier(n_estimators=i, random_state=0)
score = cross_val_score(clf, X_train, y_train, cv=3)
train_dat_array.append(np.mean(score))matplotlibでグラフ化です。
#グラフ
X_axis = np.linspace(50, 150, 100)
plt.plot(X_axis, train_dat_array)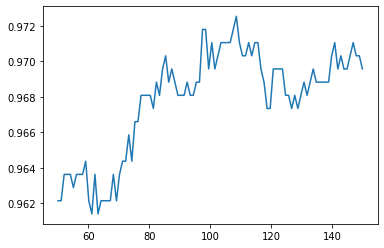
n_estimatorsが多すぎても、スコアは若干低下しますね。
「110」くらいがちょうどよさそうな感じです、デフォルトの100はかなりいい塩梅のパラメータだったんですね・・・
clf = RandomForestClassifier(n_estimators=110, random_state=0).fit(X_train, y_train)
predict = clf.predict(X_test)
print("==ClassificationReport==")
print(classification_report(y_test, predict, digits=4))==ClassificationReport==
precision recall f1-score support
0 1.0000 0.9778 0.9888 45
1 0.9583 1.0000 0.9787 46
2 1.0000 0.9773 0.9885 44
3 0.9778 0.9565 0.9670 46
4 0.9778 0.9778 0.9778 45
5 1.0000 0.9783 0.9890 46
6 1.0000 1.0000 1.0000 45
7 0.9574 1.0000 0.9783 45
8 0.9318 0.9535 0.9425 43
9 1.0000 0.9778 0.9888 45
accuracy 0.9800 450
macro avg 0.9803 0.9799 0.9799 450
weighted avg 0.9805 0.9800 0.9801 450テストデータへのスコアが、98%となりました。
若干スコアを上げることができました。
まとめ
ランダムフォレストを利用することでもかなりのスコアで分類をすることができています。しかし、サポートベクターマシンのスコアほどではありません。
アルゴリズムでどのようにスコアが変わってくるのかをいろいろ試すのも結構楽しいですね。
サポートベクターマシンの時は、データをPCAすることで、良い感じになったので、PCAをした場合のデータでも試してみたいと思います。