
細かくビニングしたらどうなるかとか、色々試したら、衝撃の事実が・・・
何か問題があったのかな?
ビニングのプログラムを色々といじっていました。前回のボストン住宅価格データの「RM」を題材に、もっと細かく分割したら精度が上がるのかな・・・とか考えつつ分割数を増やすようにしてみました。その過程で、細かくしたらテストデータの方で、データが存在しないビンが出てくるという現象があることがわかりました。
ビニングについては、こちらの記事もご参考ください。

こんな人の役に立つかも
・機械学習プログラミングの勉強をしている人
・scikit-learnで機械学習の勉強をしている人
・ビニングの勉強をしている人
ビニングの処理をまとめる
Pythonの関数でビニングに関する処理をまとめました。
まずは、ビニングの処理の流れを振り返りつつ、関数化するための入力と出力をまとめます。
ビニングの流れ
ビニングの処理はこのような流れでした。
1.ビンの範囲決定
numpyのlinspaceで範囲を指定して境界となる数値を取得。ここで入力するパラメータは「データの始まり値」と「データの終わり値」、「分割数」
2.データをビンの番号に変換
numpyのdigitizeで、どのビンの範囲に入っているか、ビンの番号にデータを変換する。ここで必要なデータは、「RMの実際のデータ」。
3.ワンホットエンコーディングとする
scikit-learnのOneHotEncoderでワンホットエンコーディングとする。
1〜3の処理を行うと、ビニングされたデータに変換することができました。
4.追加の要素
さらに、データがどのような分布で、どのようにビンの境界が引かれたかを視覚化できるように、関数の最後にmatplotlibで散布図を描きます。そのため、RMのデータに対応するy軸の「価格データ」も関数の入力とする必要がありました。
ビニングする関数の仕様
ビニングする関数として、次のような関数を作成しました。
関数名
binning_data
入力
「1.sd」:linspaceの始まりの値。
「2.ed」:linspaceの終わりの値。
「3.fnum」:linspaceの分割数の値。
「4.X」:ビニングするデータ。OneHotEncoderで利用。
「5.y」:ビニングするデータに対応する答えの価格データ。散布図用。
出力
ビニングされたデータ(二次元配列)
これで簡単にビニングできそう
関数化したビニングのプログラム
このようになりました。これで、後から「binning_data」を呼び出すと、ビニングされたデータが返ってくるようになりました。
import numpy as np
from sklearn.preprocessing import OneHotEncoder
def binning_data(sd, ed, fnum, X, y):
bins = np.linspace(sd, ed, fnum)
sel_bins = np.digitize(X, bins=bins)
encoder = OneHotEncoder(sparse=False)
encoder.fit(sel_bins)
print("カテゴリ")
print(encoder.categories_)
bin_data = encoder.transform(sel_bins)
fig = plt.figure()
ax = fig.add_subplot(111)
ax.scatter(X, y, color="green")
ax.vlines(bins, 0, 50, alpha=0.4)
return bin_dataこの関数を次のように使います。
#X_trainを6個のビンにビニング
learning_data = binning_data(3, 9, 7, X_train,y_train)
print(learning_data[:3])OneHotEncoderが自動でfitしてカテゴリを作成してくれるので、そのカテゴリも表示しています。ビニングされたデータは最初の3行だけ表示しています。
カテゴリ
[array([1, 2, 3, 4, 5, 6])]
[[0. 0. 1. 0. 0. 0.]
[0. 0. 1. 0. 0. 0.]
[0. 0. 0. 0. 1. 0.]]
こんな風にビニングするデータと、ビンがどのように分けられたかが表示されるよ。
いい感じだね〜
ボストンの価格データの「RM」の分割数を増やしたら
これを使って、分割数を増やしてやろう!と意気込んでいました。
実は、テストデータに対してビンが6個以上になると、一番小さいビンの範囲にデータがなくなるという現象が発生しました。
#X_testのビニング
test_data = binning_data(3, 9, 8, X_test, y_test)
print(test_data[:3])↓カテゴリに「1」の数字が・・・ビンにデータがないことがわかります。
カテゴリ
[array([2, 3, 4, 5, 6, 7])]
[[0. 0. 1. 0. 0. 0.]
[0. 0. 1. 0. 0. 0.]
[0. 0. 1. 0. 0. 0.]]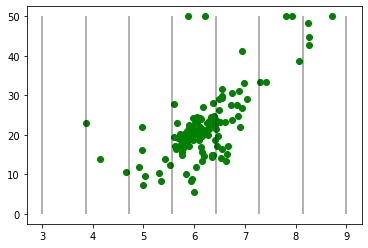
出力結果の「カテゴリ」を見てもわかりますが、「array([2, 3, 4, 5, 6, 7])」のように、「1」のビンがないことがわかります。
という感じで、ビンが7個以上の場合のボストン住宅価格データ「RM」の回帰ができませんでした。
色々勉強してみたけれど、やっぱり、特徴量の1つ分がテストデータにないから無理か、という考えに落ち着いてます。
ちなみに、話が変わるけれど、ビニングは一つの特徴量に対して個別にやっていかなければいけないみたいだね。
ビニングを色々深掘りしていくと、なんだかもっと深みにいけそうだったので、とりあえずここまでとしておきたいと思いました。