
機械学習プログラミングでアヤメのデータ分類をしたけれど、いくつかPythonの使い方で迷ったりした部分があったので、まとめたいと思います。
Pythonならではの書き方は特に、慣れてないと忘れてしまうよね。
機械学習プログラミングで学んだPythonのプログラミングに関する覚書です。C言語やC#などとは少しちがった慣れが必要で、そのあたりを中心にメモしています。
アヤメのデータ分類で機械学習プログラミングをする記事はこちらから

Python文法関連
複数の変数への一括代入
私が慣れないな、と感じたものが、train_test_splitに使われる、複数の変数に一度に値を入れることができる方法です。
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size = 0.5, stratify=y)シンプルに、値を1行で2データ入れたいときは、以下のようにできます。
panda1, panda2 = 100, 200
print(panda1)
print(panda2)それぞれ、左が左、右が右、というようにはいります。
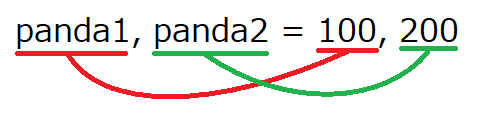
100
200個人的には、このやり方がとても慣れません・・・
for文
10回の繰り返しをするfor文です。rangeという機能を使うところがちょっと特殊な感じが否めません。
for i in range(10):
print(i)printで表示の少数を2桁までとする
機械学習の正解率を算出したりするときに、小数点がとても多くてデータが見づらくなるので、とても重宝する表記方法です。
print("{:.2f}".format(3.1415926))コロン、ドット、にーえふ
numpy
配列を初期化して作成
numpyライブラリは、pythonのlistより便利で、np.arrayのように、配列を作ることができます。0を最初から埋めた初期化されたものは、zerosという機能で作成することができます。
hairetsu = np.array([0., 0., 0., 0., 0., 0., 0., 0., 0., 0.])
print(hairetsu)
#zerosを使ったほうが短く便利
hairetsu = np.zeros(10)
print(hairetsu)[0. 0. 0. 0. 0. 0. 0. 0. 0. 0.]
[0. 0. 0. 0. 0. 0. 0. 0. 0. 0.]どちらも同様の0.0が10個はいった配列を準備する。
numpyの表示を小数点2桁までにする
#numpyの表示を小数点2桁までに変更
hairetsu = np.array([1.41421356, 1.7320508])
np.set_printoptions(precision=2)
print(hairetsu)このように、numpyの表示が小数点2桁になります。
[1.41 1.73]データの形を表示
shapeで、numpyの配列の形状を表示できます。
ただの配列のとき。
hairetsu = np.array([0,1,2])
print(hairetsu.shape)(3,)2次元配列のとき(表)
hairetsu = np.array([[0,1,2],
[3,4,5]])
print(hairetsu.shape)2行3列のように、表示されます。
(2, 3)1次元配列の方向を行から列に変える
ベクトルで転置という概念があるように、numpyの配列の方向をreshapeで変更することができます。
import numpy as np
X = np.array([1,2,3,4,5])
X.reshape(-1,1)array([[1],
[2],
[3],
[4],
[5]])行から列への変換を行うことができます。