
データの可視化がやっと実行できました。
動作環境の構築が少しめんどくさかったね。
PyTorchチュートリアルの「VISUALIZING MODELS, DATA, AND TRAINING WITH TENSORBOARD」で、GoogleColaboではエラーが出てしまうので、ローカル環境を構築しなおし、何とか動作するようになりました。今回は、チュートリアルプログラムの「PROJECTOR」についてみていきます。
今やっているチュートリアルはこちらです。

前回の記事、PyTorch+TensorBoardのローカル環境の構築についてもご参考ください。

こんな人の役に立つかも
・機械学習プログラミングを勉強している人
・PyTorchチュートリアルで勉強をしている人
・PyTorchでTensorBoardを利用したい人
4. Adding a “Projector” to TensorBoardを見る
チュートリアルの項目として「4.Adding a “Projector” to TensorBoard」を詳しく見ていきます。
「add_embedding」メソッドを使用して、高次元データの低次元表現を視覚化できます。とのことでしたが、これだけだとよくわかりませんでした^^;
#ヘルパー関数
def select_n_random(data, labels, n=100):
'''
データセットからn個のランダムなデータポイントとそれに対応するラベルを100個選択します
'''
assert len(data) == len(labels)
perm = torch.randperm(len(data))
return data[perm][:n], labels[perm][:n]
# 「select_n_random」でランダムなデータの選択
images, labels = select_n_random(trainset.data, trainset.targets)
#それぞれの画像のラベルを取得
class_labels = [classes[lab] for lab in labels]
#「add_embedding」でTensorBoardに追加
features = images.view(-1, 28 * 28)
writer.add_embedding(features,
metadata=class_labels,
label_img=images.unsqueeze(1))
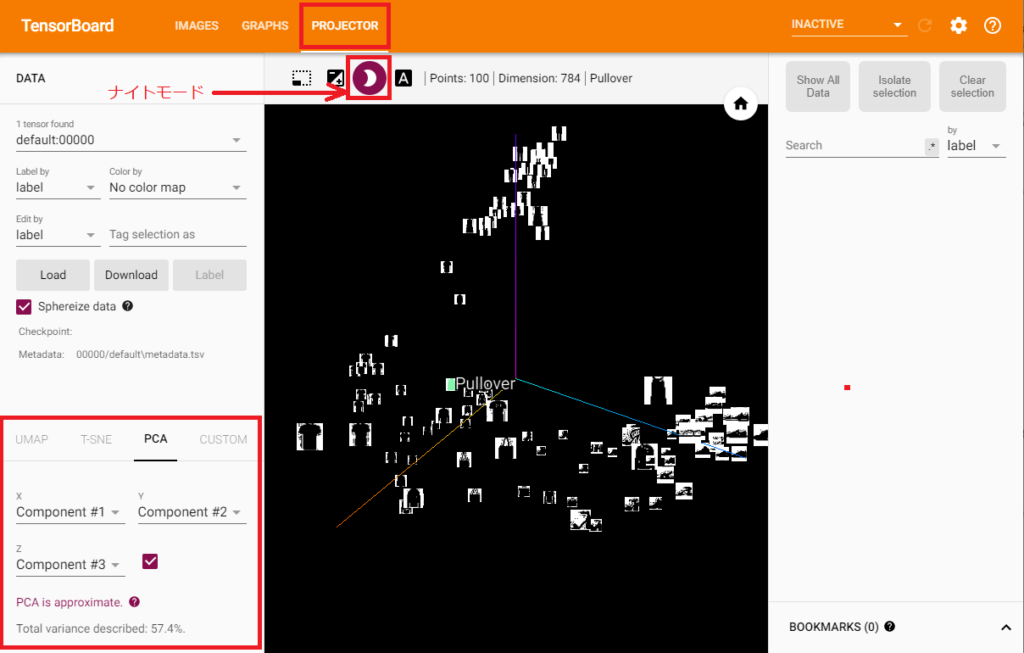
writer.close()このプログラムを実行することで、TensorBoardに「PROJECTOR」画面が追加されました。ナイトモードで見やすくしておきます。
ちなみに、TensorBoardへの反映方法は以下の通りです。(前回の記事にも書いている内容ですが、ここでも記載します。)
①上記プログラムを実行
②AnacondaPrompt(またはターミナル)のコマンドでTensorBoardを立ち上げる
macでの階層指定
ターミナルでtensorboardを起動します。私のmac環境では、「/Python」の階層にJupyterノートを配置しています。そのため、コマンドのlogdirを次のように指定したらうまく動作しました。
tensorboard –logdir=/Python/runs
windowsでの階層指定
AnacondaPromptでTensorBoardを起動します。私のwindows環境では、「C:\Users\ユーザー名(任意)\Python」階層にJupyterノートブックのPythonプログラムを保存しています。そのため、以下のようにlogdirを指定するとうまくいきました。
tensorboard –logdir=C:\Users\ユーザー名(任意)\Python\runs
TensorBoardへのアクセス
ブラウザにて、「http://localhost:6006/」を入力してTensorBoardにアクセスします。
上記のTensorBoard立ち上げは、慣れると10秒程度の作業です。そのため、TensorBoardを立ち上げて「PROJECTOR」が表示されていない場合、数秒~数十秒置いて更新ボタンを押すと表示されるみたいです。どうやら処理に少し時間がかかる模様です。
「PROJECTOR」による視覚化
PROJECTORによって、データの視覚化ができました。このデータが3次元の軸上に並んでいますが、いきなりみても、よく意味が分からなかったです。
いちばん最初に翻訳した文章の「高次元データの低次元表現を視覚化」というう点がそれを表現していて、特徴量を減少させてその特徴量ごとに並べているようなイメージです。
TensorBoardの左下に、このような画面があるのですが、ここを見るとなるほどと感じることができました。

主成分析(PCA)をおこなって、影響が高い特徴量から3次元選択し、それに基づいてデータを並べているんですね。何となくここで特徴量を抽出してそれでまとめる、ということがわかりました。
主成分分析は、データから有効な特徴量を抽出する方法で、以前にscikit-learnでも勉強しましたので、主成分分析について知りたい方はこちらの記事もご参考いただければと思います。

続きの記事はこちらになります。
