
ランダムフォレストを学んでいます。
ランダムフォレストは、決定木の進化版みたいだね。
決定木について、ある程度勉強してきたので、次は決定木の進化版のランダムフォレストについて勉強していきたいと思います。2001年に考案されたまだ比較的新しい手法ですので、期待ですね。今回は、全体的にランダムフォレストがどのようなものなのかをいろいろ調べました。
ランダムフォレストは、決定木の知識の上にあります。決定木については、こちらの記事もご参考ください。

こんな人の役に立つかも
・機械学習プログラミングの勉強をしている人
・ランダムフォレストの勉強をしている人
ランダムフォレスト
寄せ集めで頑張る
決定木のデメリットとして、
「訓練データを過学習しやすい」
という点がありました。決定木はパラメータチューニングをしていないと、すべてのデータをきっちりと分割してくれる仕事人です。逆に、これは訓練データの個性をとらえすぎたものとなって、汎化性能がなくなってしまいます。いわゆる過学習になりやすいです。
ランダムフォレストは、このような決定木を何個も作成して、平均をとることで、汎化性能をアップさせる手法です。
ひとつの訓練データしかないのにどうやって決定木をいくつもつくるんだろう??
決定木の作り方
ひとかたまりの訓練データが一つしかないと、決定木は一つしか作れないんじゃないかと思いますが、ランダムフォレストは、ひとかたまりの訓練データを「ブートストラップ法」という素晴らしい方法でひとかたまりの訓練データからいくつもの訓練データを作り出します。
まず訓練データの選択という点にランダム性が出てきます。
次に、それぞれの訓練データの特徴量をすべて利用するのではなく、何個かの特徴量をランダムに選択します。何個かの特徴量は、パラメータで設定することになります。
このようにして、訓練データからさらにいくつかの訓練データを作りそれぞれの訓練データに決定木を作ります。
二つのランダム性を導入してそのたくさんの決定木を作っているんだね。
ランダム性もパラメータで調整できるみたいだね。
scikit-learnのランダムフォレスト
scikit-learnには、
回帰に使える「RandomForestRegressor」
分類に使える「RandomForestClassifier」
が実装されています。まずは、RanomForestClassifierで乳がんデータの2特徴量のみでどのように利用するのかを試してみます。
RandomForestClassifierのプログラム
importを行い、乳がんデータを2特徴量のみに絞ります。ちなみに、RandomForestの分類器は、「sklearn.ensemble」からimportを行います。
from sklearn.datasets import load_breast_cancer
from sklearn.model_selection import train_test_split
from sklearn.ensemble import RandomForestClassifier
import matplotlib.pyplot as plt
import numpy as np
#乳がんデータ
panda_box = load_breast_cancer()
#2個分の特徴量に絞る
X = panda_box.data[:,0:2]
y = panda_box.target
#訓練データとテストデータに分割
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size = 0.25, stratify=y, random_state=0)RandomForestClassifierのパラメータ「n_estimators」は、ランダムフォレストで作成する決定木の数になります。
random_stateは、乱数を固定して、何回実行しても結果が同じように計算されるようにしています。
clf = RandomForestClassifier(n_estimators=5, random_state=0).fit(X_train,y_train)
print("訓練データへの精度")
print("{:.4f}" .format(clf.score(X_train, y_train)))
print("未知データへの精度")
print("{:.4f}" .format(clf.score(X_test, y_test)))訓練データへの精度
0.9977
未知データへの精度
0.8741乳がんデータの二次元で試すと、決定木とそんなに変わらない結果となっています。ランダムフォレストは、二段階目のランダム性が発揮されるのが特徴量の選択の部分のため、特徴量がたくさんの場合のほうが効果てきめんな気がします。
ちなみに、今回のランダムフォレストの境界線は次のようになりました。
def make_meshgrid(x, y, h=.02):
x_min, x_max = x.min() - 1, x.max() + 1
y_min, y_max = y.min() - 1, y.max() + 1
xx, yy = np.meshgrid(np.arange(x_min, x_max, h),
np.arange(y_min, y_max, h))
return xx, yy
def plot_contours(ax, clf, xx, yy, **params):
Z = clf.predict(np.c_[xx.ravel(), yy.ravel()])
Z = Z.reshape(xx.shape)
out = ax.contourf(xx, yy, Z, **params)
return out
#決定木のグラフ
fig = plt.figure(figsize=(8, 8))
ax = fig.add_subplot(111)
#グリッドのデータを作成
X0 , X1 = X_train[:,0], X_train[:,1]
xx, yy = make_meshgrid(X0, X1)
#グラフに境界線とデータをプロット
plot_contours(ax, clf, xx, yy, cmap=plt.cm.coolwarm, alpha=0.8)
ax.scatter(X0, X1, c=y_train, cmap=plt.cm.coolwarm, s=20, edgecolors='k')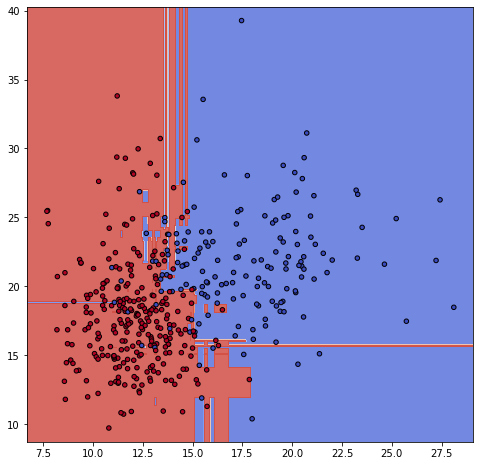
飛び地が多いね・・・