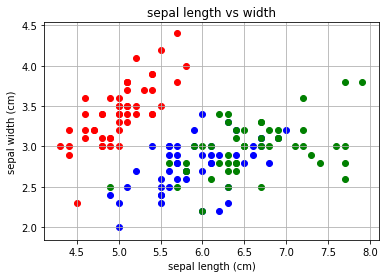
いきなり特徴量が4個のアヤメのデータの分類をしていたけれど、もっとわかりやすいところをやるべきだった・・・
機械学習のアルゴリズムを何種類か勉強してみたところ、基本的にまずは特徴量が2つのデータを分類することが理解のはじめであることがわかりました。
グラフとして視覚的にアルゴリズムがどのような境界線を引いているのか、パラメータがどのように影響するのかが視覚的に理解しやすくなります。
ということで、2次元のアヤメのデータを作るところから、Pythonプログラムを交えて記録していきたいと思います。
こんな人の役に立つかも
・機械学習プログラミングを勉強している人
・Pythonのデータ形式がいまいち慣れず、何をしているのかイメージしづらい人
・多次元のnumpy配列を2次元に変換したい人
アヤメのデータを2次元化する
2次元化、といういい感じの言葉を使いましたが、実際のところ、4つある特徴量「sepal length」「sepal width」「petal length」「petal width」の4つを「sepal length」と「sepal width」の2つの表にする、というだけです。
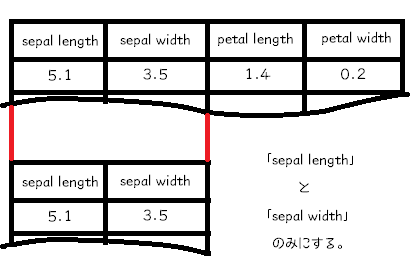
もともと、scikit-learnのアヤメのデータは、上の絵の上表のように、4つの特徴量をもつ2次元配列となっています。
「4つの特徴量をもつ2次元配列」って、「4列の表」のことだね。
この4列の表を、後ろの2つの列を取り去って、2列の表にしてしまおう、というのが今回のデータの2次元化となります。
プログラムを書いてみる
from sklearn.datasets import load_iris
panda_box = load_iris()
X = panda_box.data
y = panda_box.target
#X_2dim = panda_box.data[0:150,0:2]
X_2dim = panda_box.data[:,:2]
#アヤメのデータの形を確認
print(X.astype)
#Xのデータ数
print(X.shape)
#2次元にしたアヤメのデータの数を確認
print(X_2dim.shape)
#↓コメントアウトを取ると全データ内容がわかりますよ。
#print(X_2dim)↓のような結果になります。Xには150行2列のデータが、X_2dimには、150行4列のデータとなっていることがわかります。
<built-in method astype of numpy.ndarray object at 0x7f1de0fb2c10>
(150, 4)
(150, 2)アヤメのデータを「.data」で取得すると、numpyのndarrayという形のデータになるようです。astypeという機能で形が確認できます。実行結果の1行目のように表示されます。
ndarrayは、N dimension arrayのことで、日本語で「N次元配列」ということになります。このN次元配列の形に2次元配列が入っていることになりますね。
numpyの、特徴量を「列」、個別データが「行」として並ぶnumpyの2次元配列(ただの表)という形には慣れておくと良いと感じました。
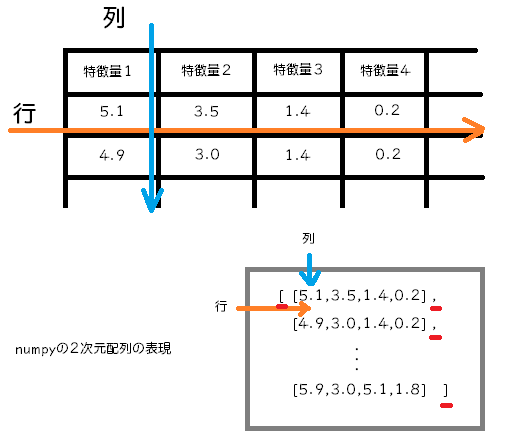
numpyのndarrayも、表のデータの形(2次元配列)は視覚的にイメージできるように。カンマ「,」の位置と、中かっこ「[」と「]」の区切りに注意ですね。
今回、プログラムで一番重要なところが、
X_2dim = panda_box.data[:,:2]の内容です。
私は、初見のとき、この意味が全然理解できませんでした^^;
アヤメのデータのdataは、
「data[ほしい行, ほしい列]」と指定することで、欲しいデータのみ抽出してくることができます。
ここで、「:」はすべてのデータの意味で、「0~150」と同じ意味になります。これは、すべての行を示すので、「:」はすべての行ということになります。
また、「欲しい列」に指定してある「:2」の意味は、「0~2」を意味しています。ちょっとわかりにくいのが、プログラムでは0が最初の数値なので、「:2」は、「0と1」を意味しています。データの最後の数字は含まない、と覚えておくとよいです。
「:」は、「どこ~どこ」という意味の「~」を示す記号なんですね。ちなみに、データの先頭と、データの最後は省略できるので、本来「0:150,0:2」と書くところを「:,:2」と省略できています。
これでやっと2次元データが作成できました。
答えデータを2クラス化
アヤメの答えデータとは「.target」に入っている0、1、2のアヤメの種類のデータを示します。
私が良く勉強し始めで混乱した点として、この答えデータを呼ぶときに「ラベル」とか「クラス」というように言われるときがあったことです。
教師あり学習、分類問題では、「ラベル」、「クラス」という言葉が出たときは、分類する答えデータのことを示すと覚えておくと理解がスムーズです。
「ラベル」とか「クラス」とかいってて混乱するけど、分類するデータのことを言っていることはわかるよ。
プログラムを書いてみる
X_2dim = X_2dim[y!=2]
y_2cls = y[y!=2]
print(X_2dim.shape)
print(y_2cls.shape)
#データの内容を見たいときは↓のコメントアウトを外せば見られるよ
#print(X_2dim)
#print(y_2cls)(100, 2)
(100,)このプログラムで重要なのが、[y!=2]という部分です。
「!=」は「~ではない」という意味の計算をするものです。yには、「target」のデータが入っていますので、「y!=2」とすることで「yのデータが2ではないもの」のデータ番号(インデックス)が得られます。
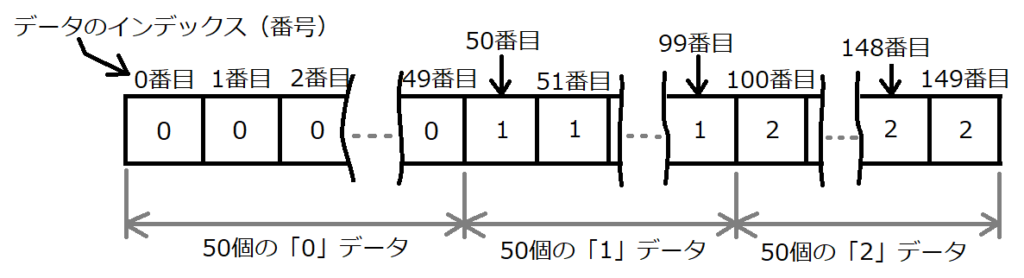
上のイメージでいくと、「y!=2」は、「y」のデータの「0番目~99番目」という意味になります。今回はデータが順番に並んでいるので、この方法でなくても単純に「0:100」とするのと同じですが、データがバラバラの場合にはこの方法が便利なので、ここで使ってみました。
アヤメのデータと答えデータはインデックスが同じ番号(データと答えが同じ並び順)なので、「y!=2」で得られるインデックスの番号を「X_2dim」のデータのインデックスとすることで答えが「2」以外のアヤメのデータのみを取り出すことができます。
Pythonのデータの魔術にはまらないように理解していきたいね。
2クラスの2次元データを視覚化
matplotlibというデータの視覚化ライブラリを利用して、データの散布図を作成しました。matplotlibをimportしています。
import matplotlib.pyplot as plt
plt.scatter(X_2dim_2cls[:50,0], X_2dim_2cls[:50,1], c="red")
plt.scatter(X_2dim_2cls[51:,0], X_2dim_2cls[51:,1], c="blue")
plt.xlabel('sepal length (cm)')
plt.ylabel('sepal width (cm)')
plt.grid(True)scatterは、以前利用したように、散布図を作成するmatplotlibの機能です。

0番目から49番目の「setosa」のデータと、50番目~99番目の「verginica」のデータをそれぞれ散布図にしています。
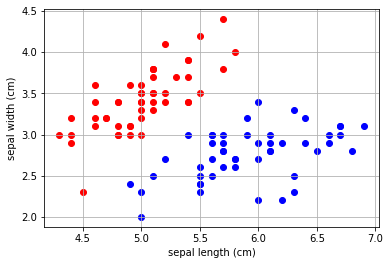
以前のアヤメデータでは、アヤメ3種類を散布図にしていましたが、今回は2種類です。ちょうど「versicolor」のデータが間引かれたようになっているのがわかります。