
サポートベクターマシンという教師あり学習の識別アルゴリズムでアヤメのデータを分類してみました。
本格的な機械学習のアルゴリズムに手を出し始めたね。
いろいろなところでサポートベクターマシンというアルゴリズムを見ましたので、やってみました。正直、現段階ではサポートベクターマシンはブラックボックスで、とりあえず以前までアヤメの分類をしていたk最近傍法をサポートベクターマシンというアルゴリズムに置き換えてみてどれくらい精度が変わったかを見るくらいの理解度ですが、少しづつ理解していきたいと思います。
こんな人の役に立つかも
・機械学習プログラミングの勉強を一緒にしたい人
・とりあえずアヤメのデータをサポートベクターマシンで分類してみたい人
サポートベクターマシン
機械学習のアルゴリズムに、サポートベクターマシンというものがあります。どうやら、ニューラルネットワークと同じように実用でよく利用されるアルゴリズムの一つとのことです。
サポートベクターマシンは、頭文字をとって「SVM」と省略されます。
正直、よくわかっていません・・・
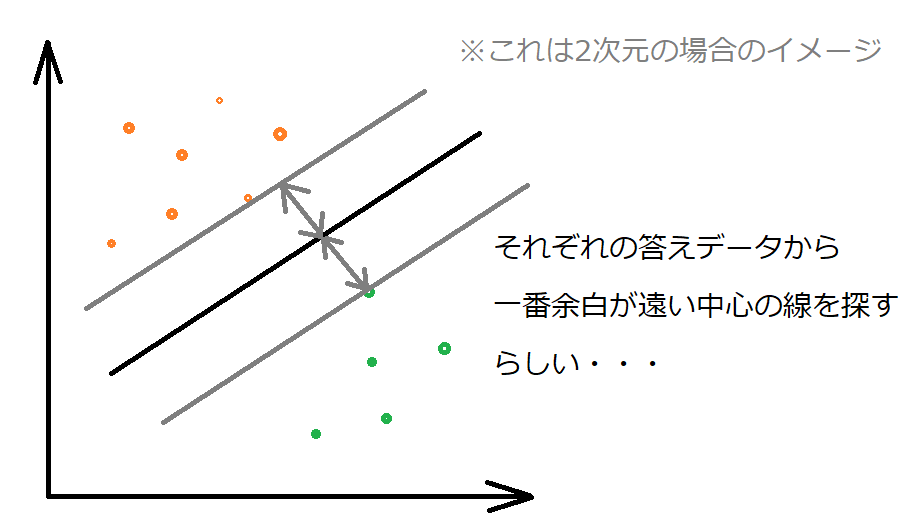
イメージとしては、答えが違うデータを分類できる境界線を探すときに、それぞれのデータが一番遠くなるちょうどよい線を見つける、みたいなイメージでした。また、この場合は、答えが2個の場合です。
ちなみに、上の図のように、答えが2個の場合を「2クラス問題」、答えが3個以上の場合を「他クラス問題」というそうです。
確かに、答えの数が多いと、境界線が一筆書きではない複雑なものになるね。
プログラム
前回までは、アヤメのデータ分類をk最近傍法で行っていましたが、それを線形サポートベクターマシンに変更しました。
まずはimport~アヤメデータ入力
読み込んだアヤメデータを訓練データとテストデータに分割している点で、一つ変更しました。
訓練データ70%、テストデータ30%としました。というのも、train_test_splitでのデフォルトの分割が75:25というものなので、それに近づける形でこの割合にしています。
テストデータ25%だと少し少ないかな、という思いで30%です 笑
from sklearn.datasets import load_iris
#ホールドアウトのimport
from sklearn.model_selection import train_test_split
#LeaveOneOutのimport
from sklearn.model_selection import LeaveOneOut
#交差検証のimport
from sklearn.model_selection import cross_val_score
#サポートベクターマシンのimport
from sklearn import svm
import numpy as np
panda_box = load_iris()
X = panda_box.data
y = panda_box.target
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size = 0.3, stratify=y)前回学んだ、LeaveOneOutにて交差検証を行います。アヤメのデータは150個で4次元の特徴量なので、計算量としてもさほど多くないため、LeaveOneOutとしています。
線形サポートベクターマシンを利用するため、「svm.SVC(kernel=’linear’)」としています。
#LeaveOneOutの作成
loocv = LeaveOneOut()
l_svm = svm.SVC(kernel='linear')
#LeaveOneOut交差検証を行う。
score = cross_val_score(l_svm, X_train, y_train, cv=loocv)
#結果の表示
print("LOOCVの結果")
print(score)
print("LOOCVの平均")
print("{:.4f}".format(np.mean(score)))LOOCVの結果
[1. 1. 1. 1. 1. 1. 1. 1. 0. 1. 1. 1. 1. 1. 1. 1. 1. 1. 1. 1. 1. 1. 1. 1.
1. 1. 1. 1. 1. 1. 1. 1. 1. 1. 1. 1. 1. 1. 1. 1. 1. 0. 1. 1. 1. 1. 1. 1.
1. 1. 1. 1. 1. 1. 1. 1. 1. 1. 1. 1. 1. 1. 1. 1. 1. 1. 1. 1. 1. 1. 1. 1.
1. 1. 1. 1. 1. 1. 1. 1. 1. 1. 1. 1. 1. 0. 1. 1. 1. 1. 1. 1. 1. 1. 1. 1.
1. 1. 1. 1. 1. 1. 1. 1. 1.]
LOOCVの平均
0.9714LeaveOneOut交差検証の結果では、97%という良い結果がでました。これを、とっておいたテストデータで評価してみます。いつも通り、fitしてscoreします。
#訓練をする
l_svm.fit(X_train, y_train)
#モデルの評価
print("{:.4f}".format(l_svm.score(X_test, y_test)))0.955695.5%と交差検証時のスコアを下回りました。
まとめ:機械学習アルゴリズムは簡単に使えるが、ブラックボックス
今回は、サポートベクターマシンを使いましたが、正直、以前までのk最近傍法の部分をサポートベクターマシンに変更しただけです 笑
scikit-learnは、機械学習アルゴリズムがブラックボックスでも、ある程度プログラムとして動作させることができるくらい体系化されていることがわかりました。
サポートベクターマシンには、いくつかのパラメータがあるみたいですが、まだ今のところしっかり理解できるところまで到達できておらず、scikit-learnのドキュメントに切り込んでいきたいなと思います。