
 パンダさん
パンダさん言葉で画像生成ができるなんて興味深いですね
 コパンダ
コパンダPythonプログラムで動作するので、試してみよう〜
StableDeffusionという言葉から画像を生成するAIがオープンソースで公開されたようで、興味深いと感じ試して見ました。無料で利用できるということなので、ここに備忘録を綴ります。
GoogleのPython環境、Colaboratoryで実行しますので、事前にGoogleアカウントが必要となります。
生成した画像例
私は、普段ブログのサムネイルなどで写真素材サイトのものを利用していますが、アニメーション風のタッチの画像はあまりないので、そういった素材があるといいな、と思い、色々試して見ました。
夜の海のシーン


キャラクター系
色々と試すといい感じの画像が出力できたと思います。


事前準備
HuggingFaceへの登録
HuggingFaceというサイトへ登録する必要があります。サイト上部の「SignUp」から、メールアドレスとパスワードを設定します。登録アドレスに確認メールが送信されるので、メールに記載されているリンクをクリックして、アカウントを有効化して完了です。
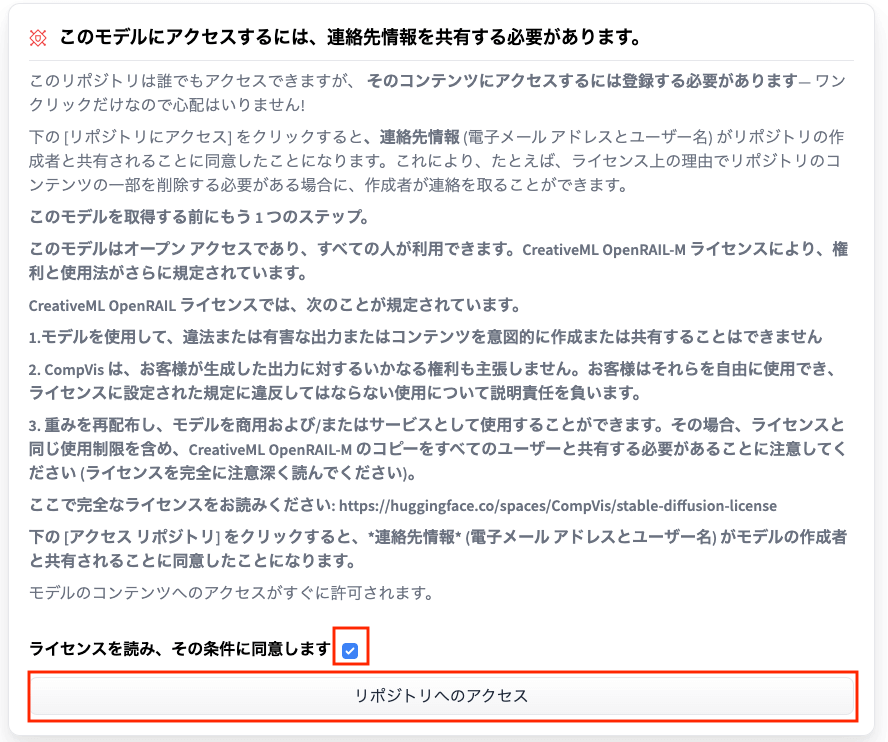
StableDiffusionライセンス同意
HuggingFaceのこちらのページに、StableDiffusionのライセンス同意画面があります。
アクセストークンの発行
HuggingFaceのアカウントメニューの「Settings」から発行できます。
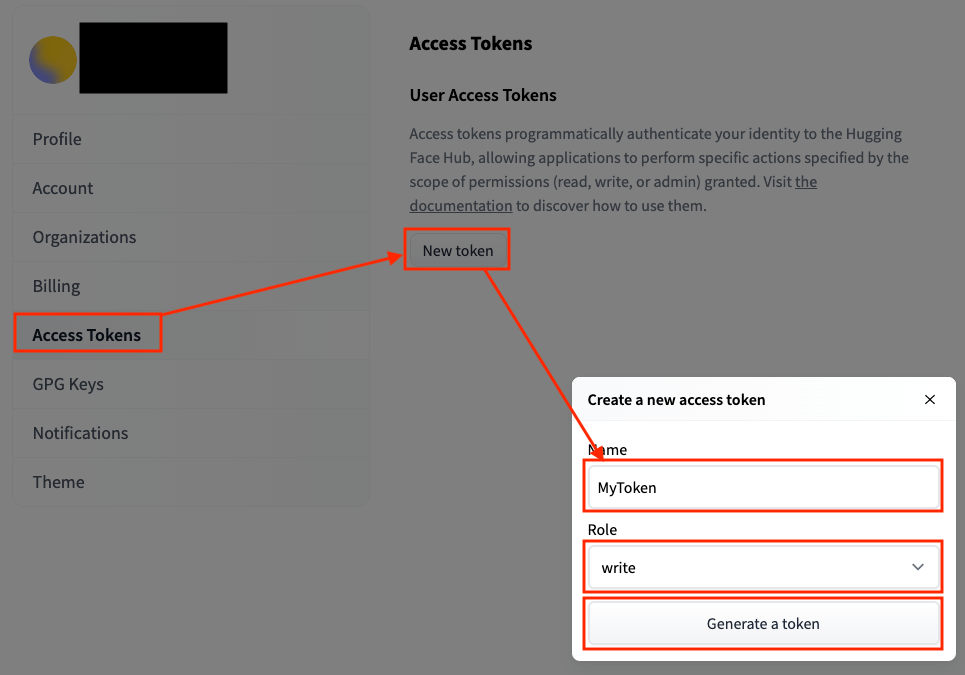
AccessTokenから、NewTokenを選択、Nameにトークンの名前(適当)とRoleをwriteにしてGenerate a tokenします。
トークンが追加されました、Showを押すと、トークンの文字列が表示されます。その右のアイコンでコピーができます。
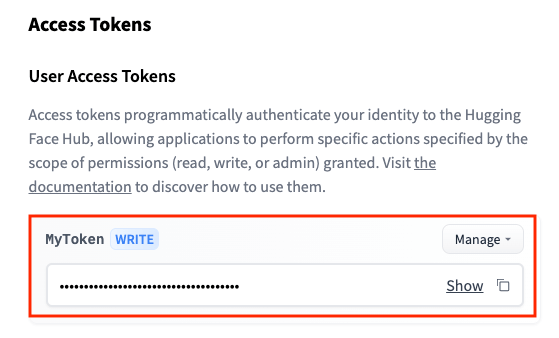
これで、StableDiffusionを利用する準備が整いました。
StableDiffusionを実行する
GoogleColaboratoryで実行します。ColaboratoryはGoogleアカウントさえあれば誰でも利用できるPythonプログラムの実行環境ですので、気軽に試すことができます。
Colaboratoryについては、当ブログも数年前に記事にしておりますので、ご参照くださいませ。ColaboratoryはGoogle検索を行うことでサービスへアクセスすることができます。または、こちらのリンクからアクセスください。

今回は、コピペで実行できるようにしていきたいと思います。
ノートブックの作成と設定
「ファイル」から「ノートブックを新規作成」で新しくプログラムを実行するファイルを作成します。ノートブックが今回StableDiffusionを実行するプログラムを書いたファイルになります。

次のようにして、ファイル名を変更することができますので、適当な名前に変更しておきます。
ちなみに、ここで作成したファイルは、Googleドライブの「Colab Notebooks」というフォルダに自動的に保存されます。
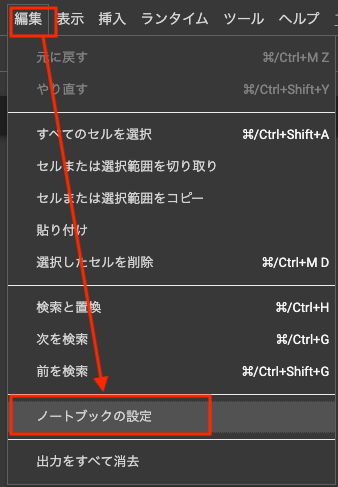
次に、ノートブックの設定でGPUを選択します。
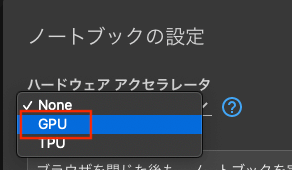
GPUを選択したら、「保存」をおします。
StableDiffusionの実行
基本的な実行手順は、こちらのサイトを参考にさせていただきました。
一つ目のプログラム
次のプログラムをcolaboのコード入力部分に貼り付けます。
!pip install diffusers==0.2.4 transformers scipy ftfy次のようにコピペしたら、左にある実行ボタンを押します。すると、すぐ下にプログラムの実行中のログ(途中経過)がずらずらと表示され始めます。実行の完了を待ちます。StableDiffusionを実行するためのプログラムの部品をインストールしています。
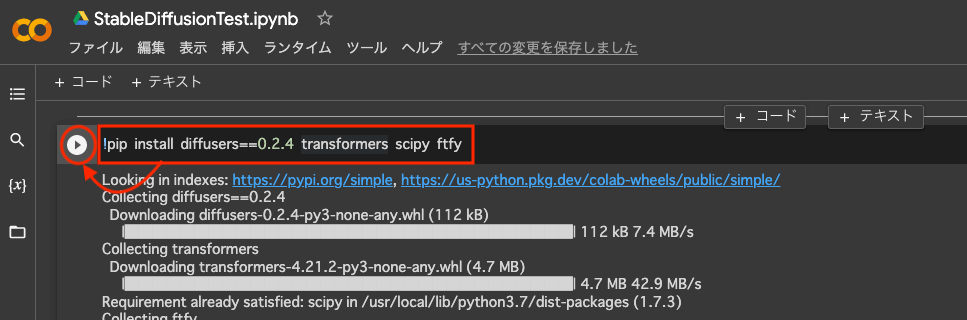
実行が完了すると、実行ボタンの三角マークのアニメーションが完了します。
二つ目のプログラム
プログラムを入力する部分を追加するため、次のように「+コード」を押して、新しく入力スペースを追加します。
次に入力するプログラムです。YOUR_TOKENに=のあとの”ここに最初に取得したトークンをコピペ”の部分には、HuggingFaceで作成したトークンをコピペします。「”ABCDEFG”」のように、””の間に文字列が貼り付けられるようにします。そして、先ほどと同じようにすぐ左の三角の実行ボタンを押してしばらく待ちます。ここは、実行時間が2分半ほどと少し待ちます。
YOUR_TOKEN="ここに最初に取得したトークンをコピペ"
from diffusers import StableDiffusionPipeline
# StableDiffusionパイプラインの準備
pipe = StableDiffusionPipeline.from_pretrained("CompVis/stable-diffusion-v1-4", use_auth_token=YOUR_TOKEN)
pipe.to("cuda")実行すると、次のように、進行状態が表示されます。完了すると、赤矢印のように緑のチェックが着きます。

三つ目のプログラム
最後に画像生成を行います。
promptのところに、生成したい画像のキーワードを入力します。英語なので、deepl翻訳などを利用して入力して見ます。
今回は、ファンタジーの海ということでFantasy seaとして見ました。
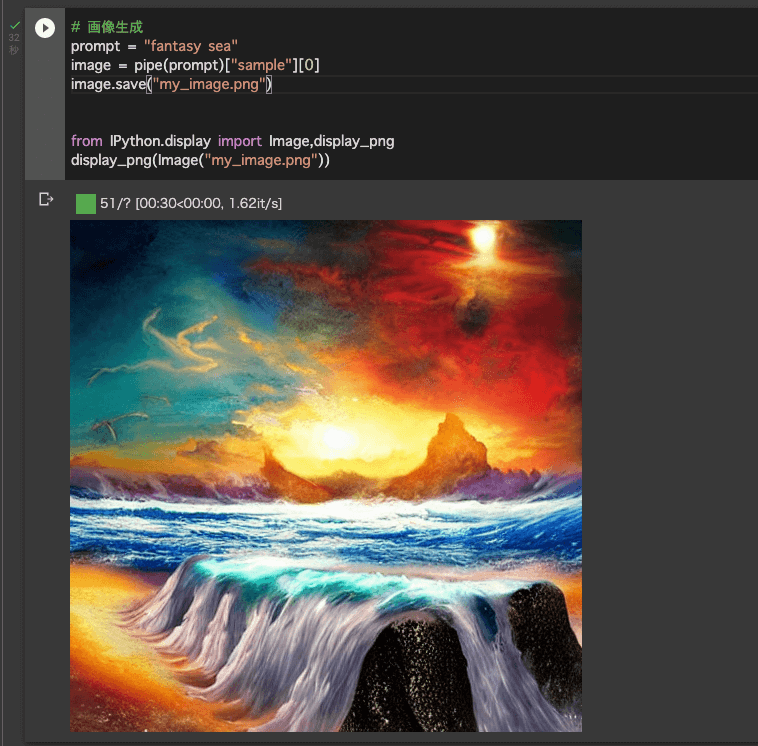
# 画像生成
prompt = "Fantasy sea"
image = pipe(prompt)["sample"][0]
image.save("my_image.png")
from IPython.display import Image,display_png
display_png(Image("my_image.png"))なんだか80年代のメタル系のアルバムジャケットみたいな画像が出てきました。結構気に入りましたw
promptの指定がかなり安定感などに影響するようです。例えば、キャラクターの生成のpromptは、次のサイトがとても参考になります。
https://note.com/6uclz1/n/nbc3d87d3e5b1
その他
promptを色々と試すことで、アニメキャラのような絵を出したりできるようで、参考サイトを元に遊んでみました。
画像サイズは、512×512、768×512、512×768を指定可能のようです。
横長を指定するときは、image=pipeの行を以下のように記載します。
image = pipe(prompt , height=512, width=768)["sample"][0]次のように諸々盛り込んだもので実行して見ました。
# 画像生成
prompt = "concept idea of the KAWAII girl with platinum straight bangs and frilly dress for digital art on pivix fanbox, beautiful face, portfolio, thick coating painting, Bold line painting, photorealistic, Fantastic, symmetrical, Arknights, Shadowverse, Azur Lane, WLOP, Makoto Shinkai, Yoh Yoshinari, Rembrandt Harmenszoon van Rijn style, Vtuber, 8k, 4K, trending on pixiv fanbox, trending on artstation, elaborate illustration, extremely high quality artwork, perfect art, brush stroke, clearly defined contours, insane detailed, dramatic lighting, very colorful, beautiful face, full body, tarot card, magical, masterpiece, intente beautiful light, high contrast in fantasy sea"
image = pipe(prompt , height=512, width=768)["sample"][0]
image.save("my_image.png")
from IPython.display import Image,display_png
display_png(Image("my_image.png"))
所感
指定するpromptのくせを見抜き、発見していく必要があるので、絵を作成するために、指示するための言葉選びの探究が必要になってきます。
欲しい画像を得るまで何度も実行する必要があります。欲しい絵が出てこないと時間が必要になる点はあまり良くありません。上の絵の生成にも1回あたりcolaboratory環境だと1分程度かかります。結構良くない絵も出てくるので、欲しい画像が出てくるまで時間がかかることもあります。
今回は、colaboratoryを利用したので、使えるリソースにも限度があります。マシンパワーが強い自分のPCで動作させれば生成時間も短縮できると思います。
ブログのサムネイル程度なら写真サイトなどで素材を探す以外の選択肢になりうるのかな〜と感じました。特に、こういったキャラクターが入ったデザインのものはあまりないので、そのような画像が気軽に欲しい場合にはいいのかなと考えています。
参考にさせていただいたサイト
https://signyamo.blog/stable-diffusion/
https://zenn.dev/6uclz1/articles/d7736b06d24f1a
https://note.com/npaka/n/ndd549d2ce556
