
テンソル型など、もう一度復習してしっかりと概念をつかんでおきたいです。
基本は大事ですよね。
PyTorchのチュートリアル、「LEARNING PYTORCH WITH EXAMPLES」をやっています。今回は、PyTorchの基本概念、Tensorのところです。サンプルプログラムにて、2層ニューラルネットワークをTensorで作成するようです。復習もかねて勉強していきます。
チュートリアルはこちらです。

本記事は、前回のnumpyで実装するチュートリアル記事の続きです。

こんな人の役に立つかも
・機械学習プログラミングを勉強している人
・PyTorchで機械学習プログラミングを勉強している人
・PyTorchのTensorの概念を勉強している人
PyTorch:Tensor
前回の記事でも見てきたように、numpyは行列を操作するうえでとても強力な機能を提供してくれます。しかし、最新のディープニューラルネットワークをはじめとする訓練には処理の高速化が必要です。numpyは、GPUを利用して数値計算を高速化することには対応していませんでした。GPUを利用することで、50倍以上の高速化をすることができるようです。
そこで、PyTorchが提供する基本的な概念である「Tensor」の出番です。Tensorはnumpy配列と概念的に同じで、Tensorもn次元配列を扱います。そして、操作するための多くの関数が存在します。特に、Tensorは背後で「計算グラフ」と「勾配」を追跡できるという点でニューラルネットワークの逆伝播の計算に役立ちます。
また、GPUにて実行することができることも有用性の一つです。
チュートリアルでは、numpyで実装したときと同じような2層ニューラルネットワークをTensorを使用して実装します。ここでも、順伝播、逆伝播を手動で実装する必要があります。
学術的な文体・・・
チュートリアルを読んでいたら、なんだか学者気分です。
numpyをTensorで置き換えてみようっていうイメージのチュートリアルですね。
チュートリアルのプログラム実装
Tensorになって、GPUを利用するかどうかの選択ができるようになりました。
GoogleColabo環境にて、GPUで動作させてみます。GoogleColaboでは、ノートブックの設定で「ランタイム」の「ハードウェアアクセラレータ」をGPUに設定する必要があります。

# -*- coding: utf-8 -*-
import torch
dtype = torch.float
#device = torch.device("cpu")
#ColaboでGPUを利用する場合、「ランタイム」->「ランタイムのタイプの変更」->「ハードウェアアクセラレータ」をGPUに変更
device = torch.device("cuda:0") # Uncomment this to run on GPU
#ここで「cuda:0」とでるとGPU利用、「CPU」とでるとCPUで動作している。
print(device)次のように、「CUDA」とでることで、GPUで動作していることが確認できます。
cuda:0Tensorで利用する機能
チュートリアルで出現したTensorの機能をまとめてみました。numpyと名前は違えど、同じイメージで利用できるものが多いです。
・randn
平均が0、分散が1の標準正規分布から値を取得して埋めます。
・mm
テンソルの掛け算を行います。
行列「(M×N)と(O×P)」というテンソル同士の掛け算を行う場合「N=O」という条件を満たす必要があります。(通常の行列積のルール)
・clump
min=0とすることで0以下を0と変換した出力を行うことができます。これで活性化関数のReLUを表現しています。
・pow
べき乗を行います。
・sum
テンソルの合計値を計算します。
・item
テンソルの中の値を数値として取り出します。スカラーなど、テンソル型のままだと扱いにくいため、itemを利用して整数などに変換します。
・clone
テンソルをコピーします。
# N :バッチサイズ
# D_in :入力次元数
# H :隠れ層の次元数
# D_out:出力次元数
N, D_in, H, D_out = 64, 1000, 100, 10
# ランダムな入力データと出力データの作成
x = torch.randn(N, D_in, device=device, dtype=dtype)
y = torch.randn(N, D_out, device=device, dtype=dtype)
# 重みをランダムに初期化
w1 = torch.randn(D_in, H, device=device, dtype=dtype)
w2 = torch.randn(H, D_out, device=device, dtype=dtype)
#損失記録用のリスト
loss_list = []
#学習率 0.000001
learning_rate = 1e-6
for t in range(500):
#①順伝播(yを予測するフェーズ)
#重みw1とxの掛け算(行列の掛け算)
h = x.mm(w1)
#活性化関数reluを適用
h_relu = h.clamp(min=0)
#中間層の出力にw2の重みを掛け算して予測出力を得る
y_pred = h_relu.mm(w2)
#二乗誤差の計算と、誤差の表示
loss = (y_pred - y).pow(2).sum().item()
loss_list.append(loss)
if t % 100 == 99:
print(t, loss)
#逆伝播:w2とw1の勾配を計算する。
grad_y_pred = 2.0 * (y_pred - y)
grad_w2 = h_relu.t().mm(grad_y_pred)
grad_h_relu = grad_y_pred.mm(w2.t())
grad_h = grad_h_relu.clone()
grad_h[h < 0] = 0
grad_w1 = x.t().mm(grad_h)
#重みの更新(確率的勾配効果法)
w1 -= learning_rate * grad_w1
w2 -= learning_rate * grad_w299 593.8939208984375
199 3.438877582550049
299 0.034401785582304
399 0.000703345809597522
499 8.761504432186484e-05GPUにすると、一瞬で500まで計算してくれます。
numpyと置き換わっただけで記述できるけれど、GPUで速度がとても向上する点が素晴らしいです。
損失をグラフとして表示してみます。
import matplotlib.pyplot as plt
plt.xlabel("train num")
plt.ylabel("loss")
plt.plot(range(500),loss_list)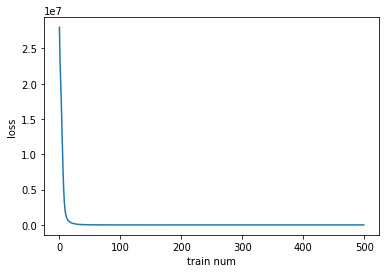
今回のプログラムも、GitHubで確認ができますので、ご利用ください。

続きの記事はこちらです。
