
GPU利用をするにあたり、何となくのコツを掴みましたので、まとめておきます。
すごく簡単なコツです。
PyTorchの基本的なチュートリアルをやってきて思いました。今までやってきたチュートリアルで、GPUを使うという点に関しては身についていないと感じました^^;
ということで、今回のチュートリアルを利用してGPUでの訓練を行わせることはできないかなと思い、GPU対応でのプログラムも作成したという経緯です。実際には、とてもシンプルなものでしたので、PyTorchのGPUを利用するという点についてまとめます。
チュートリアルは「VISUALIZING MODELS, DATA, AND TRAINING WITH TENSORBOARD」の「5.」の訓練プログラムの部分をGPU化しています。

具体的なプログラムは前回の記事をご参考ください。

こんな人の役に立つかも
・機械学習プログラミングを勉強している人
・PyTorchの勉強をしている人
・PyTorchでGPUの使い方がいまいちわからない方
PyTorchのGPUの利用
利用の際に意識すること
PyTorchでは、GPUを利用するためには、以下の2点を気にする必要がありました。
①modelのインスタンスをGPUに入れておく
netというニューラルネットのインスタンスをGPUで処理するプログラムです。
device = torch.device("cuda:0" if torch.cuda.is_available() else "cpu")
net.to(device)チュートリアルプログラムでは、netインスタンスをGPUに移動させた後、最適化手法のparameterも変更となるので、再度最適化手法のプログラムを実行しています。
②処理するテンソルをGPUに入れておく
ここが一番苦労したところです。TensorBoardを利用しない場合、以下のようにテンソルをGPUに移動させるだけで訓練ができます。
inputs, labels = data[0].to(device) , data[1].to(device)チュートリアルでは、このテンソルをTensorBoardが利用します。そのため、GPUに移動させたままのテンソルでは処理ができません。以下のように「.cpu()」メソッドを利用してCPUにテンソルとnetを戻します。
plot_classes_preds(net.cpu(), inputs.cpu(), labels.cpu()),#GPU利用時ここではCPUで処理そして、チェックポイントの処理(1000ミニバッチ毎の処理)が終わったらまたGPUへと戻します。
net.cuda(), inputs.cuda(), labels.cuda()今回のチュートリアルで、「.cuda()」と「.cpu()」というメソッドでテンソルやネットワークモデルのインスタンスをGPUやCPUへ移動させるということを学びました。PyTorchのデータが今どこにあるか、という点は他のプログラムで利用する際にも意識しておく必要が出てくるかもしれません。
GPU動作の確認方法
ちなみに、今やっているチュートリアルプログラムでは、小さな訓練のため、CPUもGPUも訓練速度は変わりませんでした^^;
そこで、以下のようにして、GPUを利用していることを確認しました。(Windowsのタスクマネージャー)
CPUモードの時は、CPUが100%となり、PCのファンがブォーンと鳴り響きます。
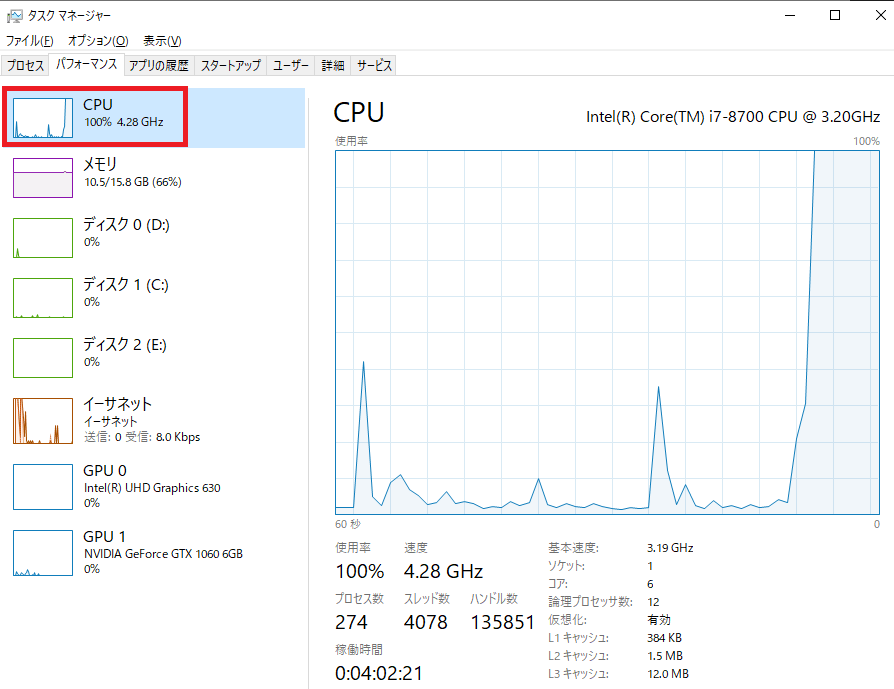
次に、GPU実行時です。
NVIDIAのGPUが少しだけ利用されているのが見えます。また、CPU利用率も20%ほどに落ち着き、PCのファンも回りません。
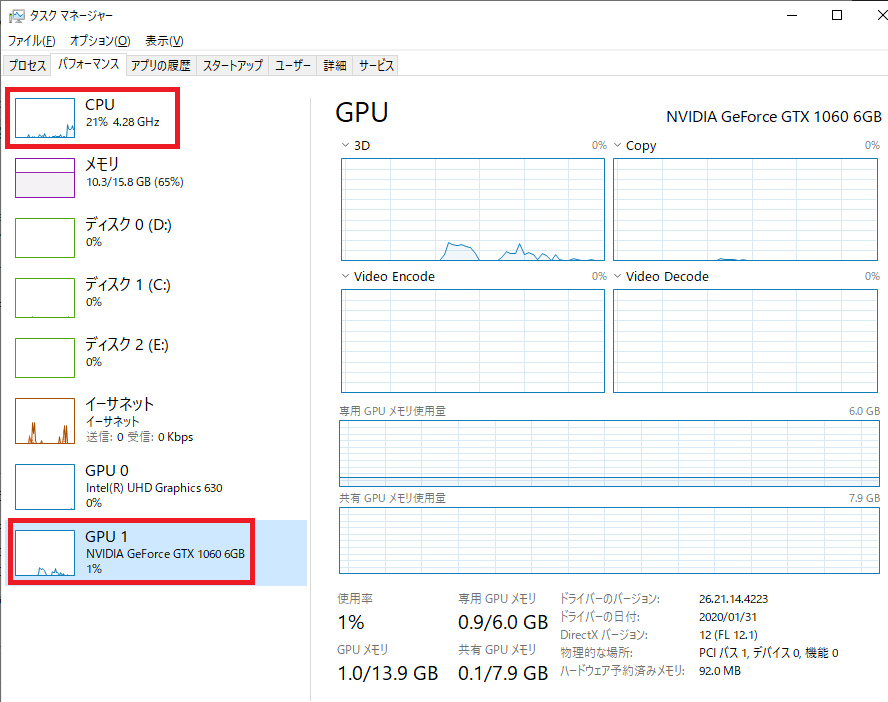
CPUではなく、GPUを利用することで、処理分散が行われて、負荷がかからなく良いのかなと感じています。
以前のDCGANのときはGPUがないと速度が天と地の差になりました(CPUだと処理が終わる目処が見えない・・・・GPUだと30分)ので、基本的にはGPUで処理を行うようにネットワークを構築していくほうが良いと思っています。また、大量のデータや、GPU処理が必要になるような訓練を行ってこそ、ニューラルネットの恩恵が受けられると思いますので、積極的にGPUを使っていきたいと思います。