pythonで、時系列データを表示して視覚的に分析したいときによく使います。
matplotlibとpandasの超ミニマムな利用をメモです。よく忘れるので^^;
目次
テストデータの準備
2019/08/28 17:38:13, 100.0 2019/08/28 17:38:14, 100.5 2019/08/28 17:38:15, 100.6 2019/08/28 17:38:16, 100.2 2019/08/28 17:38:17, 99.7 2019/08/28 17:38:18, 99.5
test_data.txt
・一列目日付データ
・二列目何かしらのデータ(価格データ的なもの)
1行毎にカンマ区切りでcsvとするデータを使用します。
ファイル名は「test_data.txt」としてpythonファイルと同階層に配置します。
pythonプログラム
#matplotlibのインポート
import matplotlib
import matplotlib.pyplot as plt
#pandasのインポート
import pandas as pd
#matplotlibの設定
plt.style.use('ggplot')
font = {'family' : 'meiryo'}
matplotlib.rc('font', **font)
#データフレームにcsvを読み込む
df = pd.read_csv("時系列データ.txt", header = None, index_col=0)
#一列目のインデックスを日付型に
df.index = pd.to_datetime(df.index)
plt.plot(df.index,df[[1]])
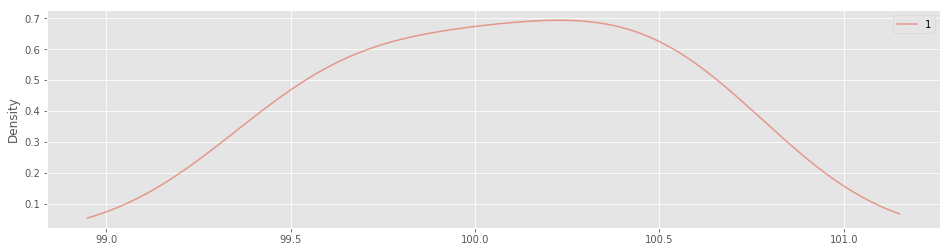
#カーネル密度推定
df.plot( y=[1], figsize=(16,4), alpha=0.5, kind='kde')
#グラフの表示
plt.show()
read_csv関数
・read_csvは、csvデータをデータフレームに読み込む関数です。
・引数に、ファイル名、ヘッダー有り無し、インデックスの列を指定します。
to_datetime関数
・テキストの日付を日付型にします。以下の図のように日付がインデックスとしてデータ表示されます。

plot(列)
・グラフ表示したい列の指定です。今回はdf[1]の列を表示するのみ。
カーネル密度推定
・データがどこに分布しているかわかりやすくなります。y=[]に、どの列か、を指定します。
show関数
・グラフを画像として表示します。