
多層パーセプトロンのパラメータ、多すぎる・・・
確かに、これ調整するの大変そうだね。言い方を変えると、自由度の高いアルゴリズム、らしいよ。
前回、多層パーセプトロン(MLP)での乳がんデータ分類を行い、ニューラルネットワークの一端を感じることができました。スコアが95%程度でしたので、もう少し頑張ってみたいなと感じ、パラメータを触ってみました。公式ドキュメントを見てもわかる通り、パラメータがとても多く、さらに中間層を検討するあたりは無限にパラメータがありますので、完全に沼だな、と感じました。わかりやすい中間層をいじり、変更することでどのように変化があったかを初心者なりに試してみました。
※最終的には、今回の考察はあまり効果がありませんでした。試行錯誤の回となりました。
前回の多層パーセプトロンで乳がんデータ分類を行った記事はこちらをご参考ください。

こんな人の役に立つかも
・機械学習プログラミングを勉強している人
・多層パーセプトロンのパラメータ調整を始めて行う人
MLPの中間層のパラメータ
多層パーセプトロンの中間層のデフォルトは、ニューロンが100個の1層となっています。
※今回は、乳がんデータなので、入力層30個、出力層1個のニューロンのモデルを考えています。
hidden_layer_sizes=[100, ]
配列の後ろに「,」が必要な点は注意ですね。
このパラメータを、次のようにすることで層を増やすことができます。
hidden_layer_sizes=[100, 100]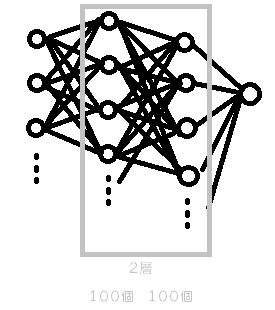
2層目にニューロン100個の層を追加しました。
また、次のような多層パーセプトロンも作成することができます。
hidden_layer_sizes=[50, 100, 30]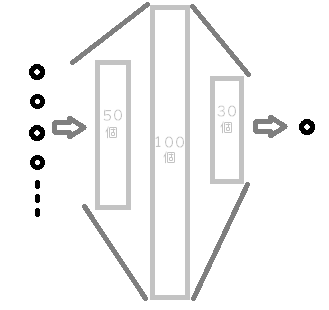
ただし、層を追加することや、層の中のニューロンを多くすればスコアが上がる、という単純なものではないため、チューニングには職人的な難しさがあります。
この人が手動で最初に設定するパラメータを機械学習アルゴリズムでは、「ハイパーパラメータ」というらしく、一方で「パラメータ」はアルゴリズムが導き出す境界線や回帰線の重みなどのことを言うらしいです。
多層パーセプトロン(ニューラルネットワーク)のハイパーパラメータを調整するための確実な方法というものは現状ないそうです。
ちなみに、optunaという自動ハイパーパラメータ調整ツールのソフトがあるみたいです。
中間層の調整アプローチ
とりあえず、次のようなアプローチで今回、中間層の変更を試してみました。
①1層目の数を変更してみて、スコアがどのようになるか観察します。
層の中のニューロンを減少させるということは、特徴量をより主となる成分にまとめるような意味合いがあるらしいです。また、逆にニューロンの数を多くすると、冗長な特徴量を増やすという意味合いで、複雑なモデルになりますが、過適合が起こる可能性もあります。
ニューロンの数を増やしたり減らしたりするだけでそんな効果があるのか。
②2層目を追加してみます。
基本的にはこの2段階だけです^^;
プログラムでやってみる
以下のプログラムで、乳がんデータをimportして、データ分割、標準化までを行いました。
from sklearn.datasets import load_breast_cancer
from sklearn.model_selection import train_test_split
import matplotlib.pyplot as plt
import numpy as np
import pandas as pd
panda_box = load_breast_cancer()
X = panda_box.data
y = panda_box.target
#訓練データとテストデータに分割
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size = 0.25, stratify=y, random_state=0)
#標準化
from sklearn.preprocessing import StandardScaler
scaler = StandardScaler()
#訓練データをもとに標準化して訓練データを標準化
X_train_scaled = scaler.fit_transform(X_train)
X_test_scaled = scaler.transform(X_test)ここからは、ひたすら交差検証で試行錯誤です。
まずは、特徴量を入力層と同じ30個のニューロンとしてみました。
from sklearn.model_selection import cross_val_score
clf1 = MLPClassifier(hidden_layer_sizes=[30, ], max_iter=10000).fit(X_train_scaled,y_train)
#交差検証を行う。
score = cross_val_score(clf1, X_train_scaled, y_train, cv=5)
#結果の表示
print("交差検証の結果")
print(score)
print("交差検証の平均")
print("{:.4f}".format(np.mean(score)))交差検証の結果
[0.97674419 0.97647059 0.95294118 0.98823529 0.98823529]
交差検証の平均
0.9765次に、デフォルトの100個より多い150個を試してみます。
from sklearn.model_selection import cross_val_score
clf2 = MLPClassifier(hidden_layer_sizes=[150, ], max_iter=10000).fit(X_train_scaled,y_train)
#交差検証を行う。
score = cross_val_score(clf2, X_train_scaled, y_train, cv=5)
#結果の表示
print("交差検証の結果")
print(score)
print("交差検証の平均")
print("{:.4f}".format(np.mean(score)))交差検証の結果
[0.96511628 0.98823529 0.96470588 0.98823529 0.98823529]
交差検証の平均
0.9789あんまり変化ないね・・・・
ニューロンの個数をたくさん増やしてみます。1000個にしてみました。
from sklearn.model_selection import cross_val_score
clf3 = MLPClassifier(hidden_layer_sizes=[1000, ], max_iter=10000).fit(X_train_scaled,y_train)
#交差検証を行う。
score = cross_val_score(clf3, X_train_scaled, y_train, cv=5)
#結果の表示
print("交差検証の結果")
print(score)
print("交差検証の平均")
print("{:.4f}".format(np.mean(score)))交差検証の結果
[0.97674419 0.98823529 0.96470588 0.98823529 0.98823529]
交差検証の平均
0.9812多くしたら少しだけスコアが上昇したように見えます。
次に、2層目を増やしました。2層目もニューロンの個数を何回も試して14個にしてみました。
from sklearn.model_selection import cross_val_score
clf4 = MLPClassifier(hidden_layer_sizes=[1000, 12], max_iter=10000).fit(X_train_scaled,y_train)
#交差検証を行う。
score = cross_val_score(clf4, X_train_scaled, y_train, cv=5)
#結果の表示
print("交差検証の結果")
print(score)
print("交差検証の平均")
print("{:.4f}".format(np.mean(score)))交差検証の結果
[0.97674419 0.98823529 0.96470588 0.98823529 1. ]
交差検証の平均
0.9836交差検証では、良くなっているように見えます。今までの学習させたMLPのすべてをテストデータで評価してみます。
predict = clf1.predict(X_test_scaled)
print("Accuracy1")
print(accuracy_score(y_test, predict))
predict = clf2.predict(X_test_scaled)
print("Accuracy2")
print(accuracy_score(y_test, predict))
predict = clf3.predict(X_test_scaled)
print("Accuracy3")
print(accuracy_score(y_test, predict))
predict = clf4.predict(X_test_scaled)
print("Accuracy4")
print(accuracy_score(y_test, predict))Accuracy1
0.965034965034965
Accuracy2
0.958041958041958
Accuracy3
0.958041958041958
Accuracy4
0.951048951048951交差検証のスコアが良くなったのですが、テストデータへのスコアが、一番最初の1層30個のほうが良いという形になりました。また、2層にしていろいろ調整したものでも、デフォルトの設定とあまり変化がないという結果になってしまいました・・・
初めてにしては、頑張ったかも・・・
だんだんめんどくさくなってない?