
AIプログラミングができるようになるために今日も少し勉強したよ。
今日はどんなことを勉強したのかな?
前回は、人工知能とはどんなものかを記事にしました。より具体的に機械学習というプログラミング分野をPythonで勉強していけば最近はやりのいい感じなアプリなどが作れそうということがわかりました。

前回の内容では、機械学習について目的に応じてその種類があることについて触れましたが、この部分をより掘り下げて勉強しました。
こんな人の役に立つかも
・人工知能を実現している機械学習の技術の種類をおおざっぱに知りたい
・人工知能技術の中のディープラーニングの立ち位置が知りたい
機械学習には3つのカテゴリがある

教師あり学習
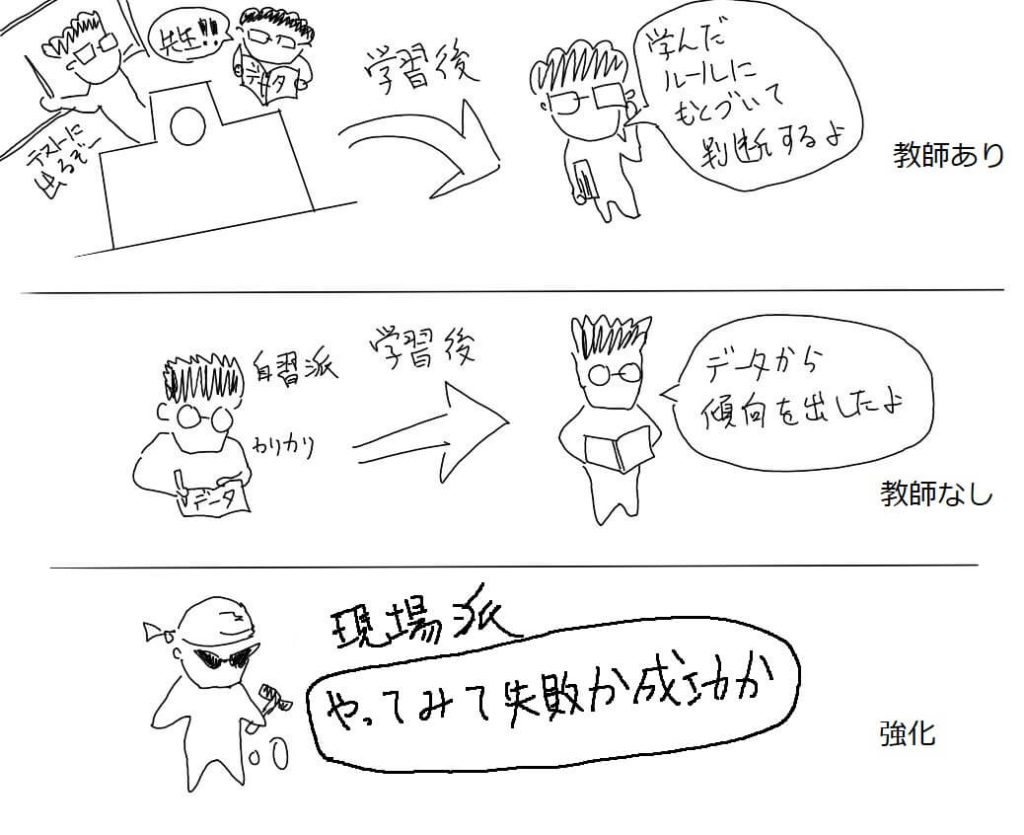
「教師あり学習」は、データとその答えを一緒に与えて学習させます。
答えがあるデータを「訓練」をさせます。
答えがあるデータとは、例えば、
・「甘さ:5、重さ:5」は「おいしいリンゴ」
というデータは、最初の「甘さ:5、重さ:1」がデータとなり、答えが「おいしいリンゴ」となります。こうした特徴データと答えデータが両方存在しているデータを訓練するのが教師あり学習です。
そうすれば、答えのないデータを入れたときにその答えを出すことができるはずです。このようなものを作るのが教師あり学習です。
「教師あり学習」の目的には、次のようなものがあります。
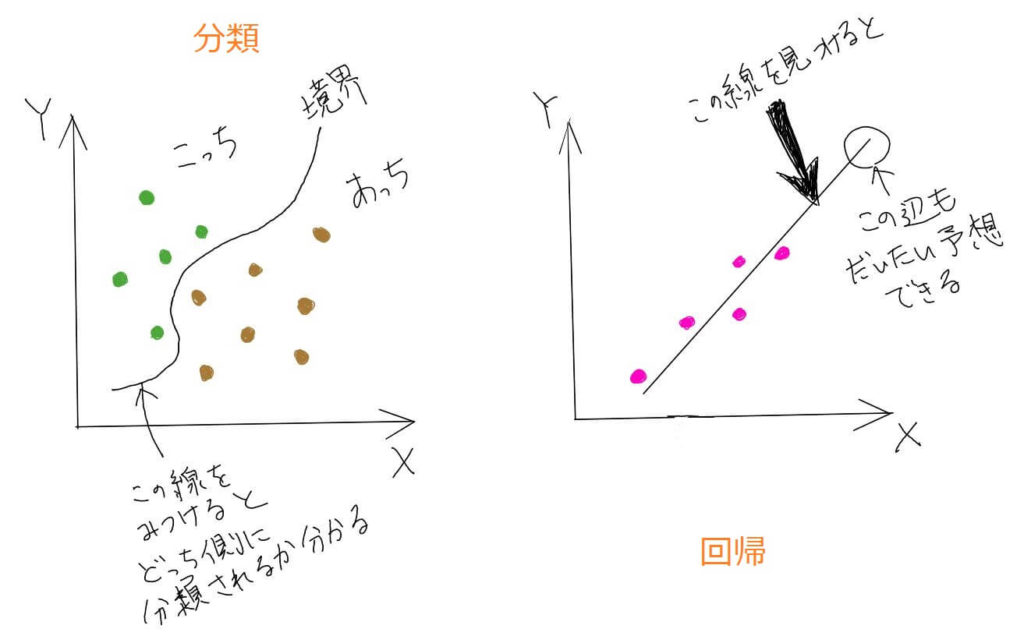
分類
たくさんのデータから、データのの答えが境界線を見つけます。
見つけた境界線をもとに、未知のデータがどこに属するか判断します。
「甘さ:5、重さ:5」は「おいしいリンゴ」
「甘さ:2、重さ:2」は「不良品リンゴ」
というデータが取れたときに、「甘さ」と「重さ」というデータをもとにして答えである「おいしいリンゴ」か、「不良品リンゴ」かを分類するイメージです。
回帰
たくさんのデータとその答えから、予測値を出せるようにします。
予測というだけあって、必ず正解するというものではありません。
例えば、次のようなデータがあったとします。
「部屋数:3」は「家賃:90000」
「部屋数:1」は「家賃:30000」
部屋数というデータから家賃という価格を予想します。「部屋数:2」のときはいくらの家賃か?というようなときに、データをもとに予測してくれます。
分類と回帰は両方とも、数学でいう関数、y=f(x)みたいなものを算出するイメージです。
学習した時点とこれから判断する時点でどんどん外部環境が変化していく場合、対応できなくなりますね。
外部環境に依存しないものに適しています。
画像認識は教師あり学習に適していると考えられます。「猫」の画像は人間が滅びるまで「猫」と認識され続けられるべきであるので、外部環境の変化はないといえます。
プログラミングするときはどうするの?
この線の見つけ方として、
・SVM(サポートベクターマシーン)
・ニューラルネットワーク
・ディープラーニング
等の方法があるとのことです。チャレンジしたいですね。
教師なし学習
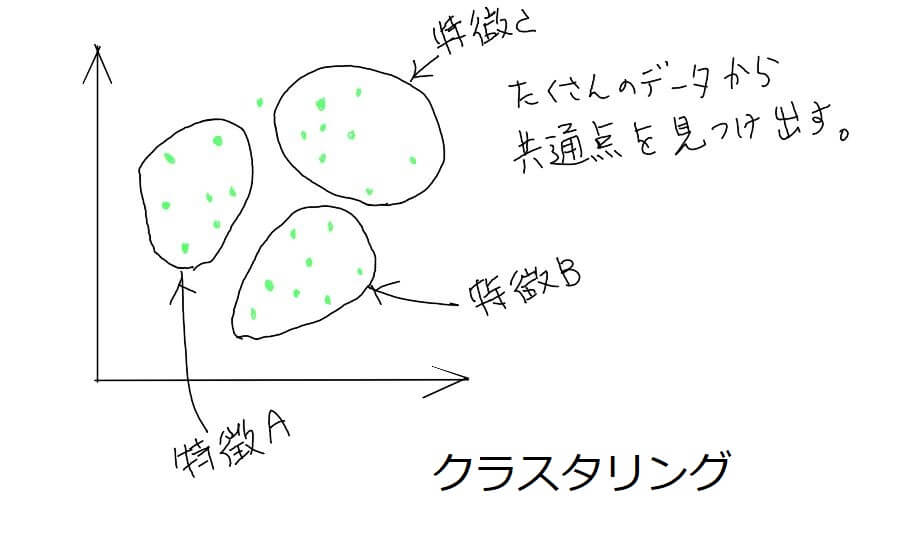
たくさんのデータの集まりから、このデータにはこんな特徴がありました、という共通点を見つけるのに特化したやり方です。
先ほどの教師あり学習とは違い、答えのないデータを与えて、そのデータにどんな特徴があるのかを見つけ出す手法です。
実用的には、教師なし学習に与えるデータを作成するときに活躍します。
・クラスタリング
・次元の削減
最初に例にしたリンゴのデータでは、「甘さ:5、重さ:5」は「おいしいリンゴ」というデータでした。このデータには、「甘さ」という特徴と「重さ」という特徴の2つがあります。こういったものをデータの「特徴量」といいます。データには特徴量が何個も含まれる場合があります。
「甘さ:5、重さ:5、大きさ:5」は「おいしいリンゴ」
というデータになったとき特徴量は3個に増えました。
この時、データの次元数は3次元ということになります。特徴量の数が次元数になるんですね。
最初に解説した、教師あり学習では、特徴量が多すぎると、性能が低下することがあります。こうしたとき情報の本質的な部分を維持しながら特徴量を減らすということが「次元の削減」になります。
プログラミングするときはどうするの?
・PCA(主成分分析)
・k平均法
・ディープラーニング
等の方法があるらしいです。
強化学習
教師あり学習や教師なし学習は、過去のデータをもとに答えを出すという処理でした。
それに対し、チェスなどのように、常に外部の環境が変化していっている中で最も適切な答えを出すという繰り返しをするときには、教師あり学習や教師なし学習では力不足です。
強化学習は、ある環境の中で、失敗を経験して成功に近づけていくというやり方です。常に外部環境が変化するようなときに、その場で一番正解と思われる答えを出すというような場合に効果があります。
ただ、強化学習は失敗することが必要なので、現実世界で失敗させるのでなく、シミュレーション環境を作る必要などがあり、現段階では、ゲームの自動操作等にとどまっているとのことです。これからどんどん出てきそうですね。
プログラミングするときはどうするの?
・Q学習
等の方法があるらしいです。
教師あり学習、教師なし学習は優等生、強化学習は成り上がりということだね。
まとめ:機械学習で知りたかったことに使づいた気がします
教師あり、教師なしと強化学習の違い
「教師あり学習」、「教師なし学習」は、データを準備して学習させる、という段階が必要です。
この二つの学習は、学校で必要なことを学び、社会人になってもその知識ないで仕事をするイメージでしょうか。
一方で、「強化学習」は実際の環境(またはシミュレーション)に入り、失敗や成功にポイントを付け、そのポイントを最大化するように動きます。
強化学習は、人間が経験で学び、より良い結果を出せるように修正していく、というようなイメージに似ていますね。
このような機械学習の性質を組み合わせると、人間の能力を模倣できそうですね。
ディープラーニングは、機械学習という分野の一部
ずっと気になっていたディープラーニングという言葉がありました。名前から何かすごいことをしている感は伝わってくるのですが、このディープラーニング、という言葉から調べ始めても一向に理解が進みませんでした。
今回、機械学習を体系的に学習しようと思い、調べていったら、ディープラーニングは、機械学習の「教師あり学習」や、「教師なし学習」というものを作るためのアルゴリズムということがわかりました。
ブロック崩しを学習させたものは、DeepLearningとQ学習を組み合わせた学習方法らしい。勝手にプロ級の操作を覚えていくのは見てて面白いよ。
機械学習プログラミングを始めるために、PythonプログラミングのAnaconda環境を入れました。

Pythonの機械学習プログラミングで使うプログラミングの追加機能、scikit-learnライブラリについて記事にしました。
