
LeaveOneOutっていう分割方法もあるみたいだ
交差検証の分割数をデータ数分やるやつだね。(しったかぶり)
前回までに、機械学習のアルゴリズムを検証するため、交差検証、パラメータの調整、テストデータの評価等を行いました。
今回は、交差検証についてもう少し勉強しました。交差検証のLeaveOneOutという手法を学びましたので、その様子をつづります。
こんな人の役に立つかも
・LeaveOneOut交差検証について知りたい方
・機械学習プログラミングの勉強をしている方
・LOOCVのサンプルプログラムを見たい方
LeaveOneOut交差検証による分割方法
LeaveOneOut交差検証は、LOOCVと呼ばれます。
交差検証のテストデータを1個にしたものです。アヤメのデータを例にすると、1個がテストデータ、そのほか149個が訓練データとなる分割方法です。そして、交差検証なので、アヤメのデータの場合、150パターンの訓練と評価が行われます。名前の通り、LeaveOneOut、テストデータ一つ残しの交差検証となります。
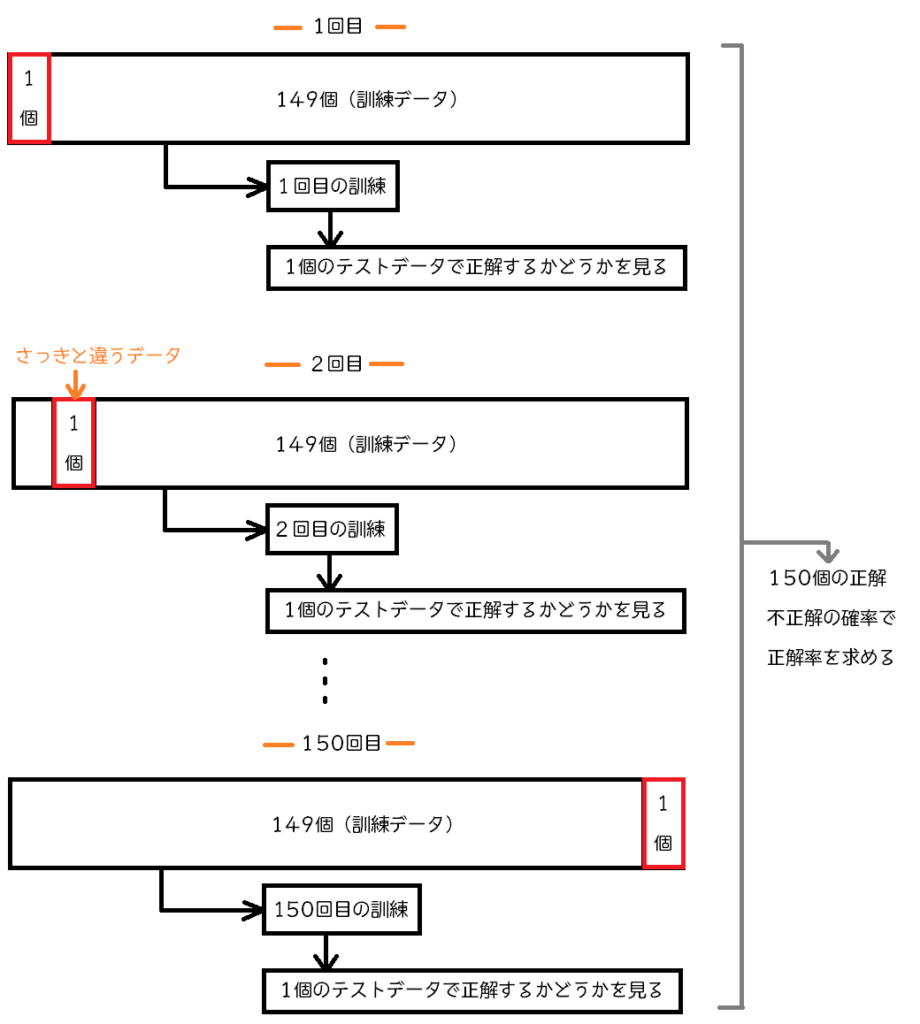
データ数と同じ数の「学習→評価」の流れを行うので、データ数が多い場合や、マシンパワーが弱い場合は実行する時間がかかります。データの大きさに応じて選択したいところですね。
すごく体育会系ということがわかります。体育会系交差検証でもいいような気がします。
LOOCVを動かしてみる
まずは、importします。
今までのimportの集大成みたいな感じになっています。いつも通りのアヤメのデータを読み込みです。train_test_splitで事前に、交差検証で検証するための訓練データとテストデータに分割します。事前に分割については、機械学習アルゴリズムのまた、評価の流れについては、前の記事をご参考ください。
#LOOCV(LeaveOneOut CrossValidation)
from sklearn.datasets import load_iris
#ホールドアウトのimport
from sklearn.model_selection import train_test_split
#交差検証のimport
from sklearn.model_selection import cross_val_score
#LeaveOneOutのimport
from sklearn.model_selection import LeaveOneOut
#k-最近傍法のimport
from sklearn.neighbors import KNeighborsClassifier
import numpy as np
panda_box = load_iris()
X = panda_box.data
y = panda_box.target
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size = 0.5, stratify=y)今回も、k最近傍法を例に交差検証を行います。
LeaveOneOutCVは、cross_val_scoreの使い方の一部なので、cvパラメータにLeaveOneOutの設定を行います。LeaveOneOutの設定を行うためには、loocv変数(命名は自由です)にLeaveOneOut()という機能でLeaveOneOutの設定を作成します。これをcvパラメータに指定するという流れでcross_val_scoreをLeaveOneOutの設定にできます。
knc = KNeighborsClassifier(n_neighbors = 9)
#LeaveOneOutの作成
loocv = LeaveOneOut()
#LOOCVを行う。
score = cross_val_score(knc, X_train, y_train, cv=loocv)
#結果の表示
print("LOOCVの結果")
print(score)
print("LOOCVの平均")
print("{:.4f}".format(np.mean(score)))train_test_splitで分割した訓練データ、75個分についてLeaveOneOut交差検証を行っていますので、75個の結果が出てきますね。テストデータが1つなので、正解率は100%(1.0)または0%のどちらかになっています。
これらのすべての結果を平均すれば、正解率が出てきます。
numpyのmeanという平均を出す機能で計算しています。また、小数点以下4桁で表示するようにしています。
訓練データの交差検証では、98%という高い結果が出ていますね。
LOOCVの結果
[1. 1. 1. 1. 1. 1. 1. 1. 1. 1. 1. 1. 1. 1. 1. 1. 1. 1. 1. 1. 1. 1. 1. 1.
1. 1. 1. 1. 1. 1. 1. 1. 1. 1. 1. 1. 1. 1. 1. 1. 1. 1. 1. 0. 1. 1. 1. 1.
1. 1. 1. 1. 1. 1. 1. 1. 1. 1. 1. 1. 1. 1. 1. 1. 1. 1. 1. 1. 1. 1. 1. 1.
1. 1. 1.]
LOOCVの平均
0.9867実際に、k最近傍法に訓練データを訓練させて、先ほど分割して取っておいたテストデータ「X_test」と「y_test」で評価してみます。
#訓練をする
knc.fit(X_train, y_train)
#評価
print("{:.4f}".format(knc.score(X_test, y_test)))今回は、訓練データのLeaveOneOut交差検証による評価を下回る96%という評価結果になりました。
0.9600LOOCVが訓練データでの評価は一番よさそうな気がしたけど、どうなのかな・・・まだ使いどころは明確にわからないな。今後やっていくうちに使いどころも考えよう。