
前回の続き、tensorflowのfashinMNISTの予測部分です。
前回はチュートリアルの予測の前までやったね。
前回はKeras+TensorFlowでニューラルネットワークのモデル作成から訓練を行い、テストデータで評価を行いました。

Googleのチュートリアルの後半では、モデルの予測、という項目がありますので、今回はモデルの予測の部分も進めていきたいと思います。
Googleのチュートリアルはこちらのものを利用しています。
こんな人の役にたつかも
・機械学習プログラミングの勉強をしている人
・Keras+TensorFlowでFashionMNISTのチュートリアルに取り組んでいる人
・Keras+TensorFlowで機械学習プログラミングを始めようとしている人
モデルの予測
前回までで作成したmodelという変数に、「X_train」の60000個のデータで訓練されたニューラルネットワークが入っています。
このmodelにデータを入力することで、予測値である「入力された画像が10種類の衣料品のうちのどの画像なのか」を得ることができます。
作成した「model」には、「predict」という機能がありますので、これで予測値を得ることができます。これもscikit-learnと同じですね。
predictions = model.predict(X_test)kerasってscikit-learnを利用しているととっつきやすいんだね。
X_testには、テストデータ10000個が入っていますので、予測値「predictions」も10000個の答えが入ってきます。
一番最初の答えデータを確認するには、次のように見ることができます。
predictions[0]一つの答えに10個の数値が出てきました。
array([2.3907173e-08, 7.1658306e-08, 6.2209122e-09, 2.6316391e-09,
1.8157003e-09, 1.1815609e-03, 2.5520361e-08, 4.8974012e-03,
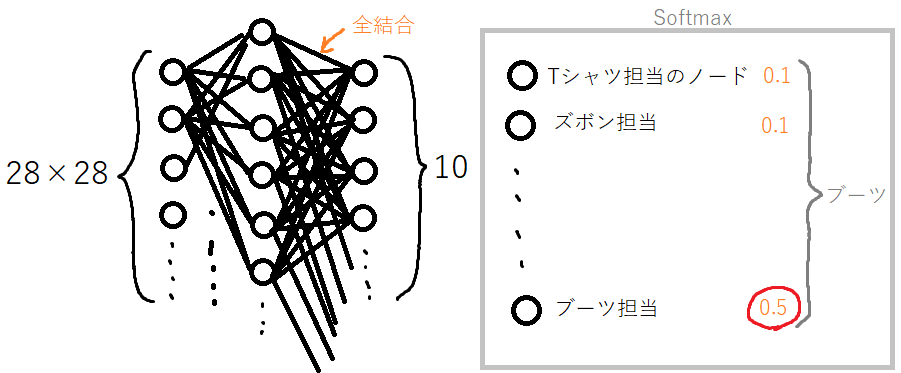
1.2693299e-08, 9.9392092e-01], dtype=float32)これは、ニューラルネットワークの出力層が10個のノードがあるため、10個の答えが存在していることになります。
これらの数値が示しているのは、確率で、今回の場合、「9.9392092e-01」わかりやすくすると、「0.9939・・・」(e-01は10のマイナス1乗なので、0.1をかけます。)ということで圧倒的に答えの確率が一番高いのが「9」の答えということになります。
今は目視で一番確率の高いものを選択しましたが、これをプログラムで行うと、次のようになります。
np.argmax(predictions[0])numpyの「argmax」という機能を利用します。これは、配列の中の最大値を選択して返して、何番目の要素が最大化を教えてくれるものです。
実行すると、次のようになります。
9テストデータの答えを確認してみます。
y_test[0]9とりあえず一番最初のデータは予測値と答え一致しました。
このように、出力が確率で出力されるという点は、ニューラルネットワークの出力層の活性化関数の「softmax」によるもので、実際にどのように動作しているかを体感することができました。
scikit-learnのMLPでもそうでしたが、多クラス問題の出力の活性化関数は「softmax」で出力するという点は一般的のようです。
Kerasに与えるデータの形
チュートリアルでは、答えの確率を可視化することでどこがどのように間違っているかをわかりやすくしています。
この部分は、データによるので、(例えば、ConfusionMatrixを使ったりすることもできる)今回はそのあとの1枚の画像に対する予測の部分にいきました。
まずは、入力するための1枚の画像をテストデータから取ってきます。(本来は新たに外部から撮影したりして取り入れると思います。)
# テスト用データセットから画像を1枚取り出す
img = X_test[0]
print(img.shape)(28, 28)28×28のデータですので、縦横のデータをもつ2次元配列であることがわかります。
Kerasで作成したニューラルネットワークには、「バッチ」というデータ形式でデータを入力する必要がありますので、次のように3次元のテンソル形式のデータにする必要があるとのことです。
# 画像を1枚だけのバッチのメンバーにする
img = (np.expand_dims(img,0))
print(img.shape)(1, 28, 28)numpyのexpand_dimsは引数に(配列,形状のNo)と指定すると次の図のように、1が追加されます。
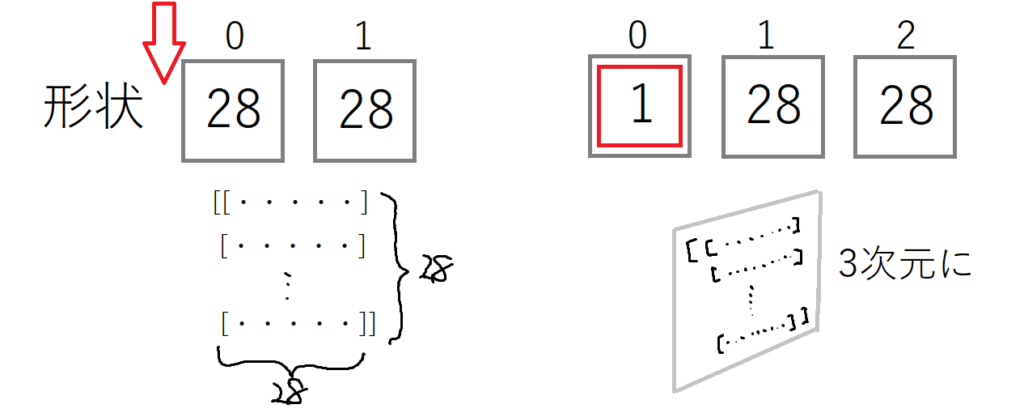
これにより、一番最初の訓練データやテストデータと同じデータ形状に揃えることができました。