
引き続き、kaggleのチュートリアルを行っています。
早速ランダムフォレストなんて、実用的だね。
前回のKaggleでタイタニック号の生存者予測チュートリアルの続きを行いました。今回は、プログラムでスコアを出す部分がメインとなります。チュートリアルで早速ランダムフォレストで予測をしていますので、かなり実用的なチュートリアルだなと感じています。
今回の記事は、Titanicのチュートリアルpart3に独自の見解を加えたものとなります。

前回の記事については、こちらもご参考ください。

ランダムフォレストについては、こちらの記事もご参考ください。

こんな人の役に立つかも
・機械学習プログラミングを勉強している人
・Kaggelでタイタニック号のチュートリアルをしている人
・Kaggleでプログラミング、スコアの提出の流れを知りたい人
チュートリアルプログラミングPart3から
まずは、「gender_submmision.csv」の回答(女性全員生存、男性全員死亡の回答)がどれほどのものかを確認してみます。これを確認することで、性別に対する生存率、という特徴量がどれくらい有効であるかを確認する流れとなっています。
性別での生存率を計算
pandasのDataFrameを利用して、「女性の行」を取り出し、「Survived」の列を取り出しています。
DataFrameで特定のデータを取り出すときに、「.loc」を利用します。そして、そのあとに[行][列]と指定して特定の列のみを取り出しています。今回は、[femaleの行][survivedの列]を指定することで、女性の「生存」列のみを取り出しています。
中身が気になるので、「print」で確認してみましょう。
women = train_data.loc[train_data.Sex == 'female']["Survived"]
#確認
print(women)
rate_women = sum(women)/len(women)
print("% of women who survived:", rate_women)sum(women)とすることで、Survived列のデータを合計しています。Survived列は、0または1のデータなので、データを合計することで、生き残った女性の数となります。それを、len(women)でデータの全体数で割ることで、「train.csvのデータの女性の生存率」を計算しています。
1 1
2 1
3 1
8 1
9 1
..
880 1
882 0
885 0
887 1
888 0
Name: Survived, Length: 314, dtype: int64
% of women who survived: 0.7420382165605095訓練データ内に含まれる女性の生存率は、だいたい74%程度のようです。
次に、男性にも同様に生存率を計算してみます。
men = train_data.loc[train_data.Sex == 'male']["Survived"]
rate_men = sum(men)/len(men)
print("% of men who survived:", rate_men)% of men who survived: 0.18890814558058924だいたい19%くらいですね。
単純に性別で生存率を分けるだけでも結構いい形の数値になっています。ということでチュートリアルでは、性別はこの課題に対して、強力なデータであると結論づけています。
ただ、一つの列(特徴量)だけではなく、他の列も考慮してもっと予測精度を向上させることができるはずで、これを自動化するのが機械学習アルゴリズムです、という流れになっていきます。
ランダムフォレストの訓練
まずは、データの作成です。
答えデータとして「Suvived」列を取り出した「y」というデータを作成しています。
また、訓練用データはpandasの「get_dummies」という機能を利用して加工していあます。具体的には、実行してみるとわかります。
まずは、利用する列を「features」に指定します。今回は4つの列を利用するようです。
features = ["Pclass", "Sex", "SibSp", "Parch"]
#get_dummiesをしない場合
X = train_data[features]
print(X) Pclass Sex SibSp Parch
0 3 male 1 0
1 1 female 1 0
2 3 female 0 0
3 1 female 1 0
4 3 male 0 0
.. ... ... ... ...
886 2 male 0 0
887 1 female 0 0
888 3 female 1 2
889 1 male 0 0
890 3 male 0 0
[891 rows x 4 columns]次に、get_dummiesをしてみます。
#get_dummiesをした場合
X = pd.get_dummies(train_data[features])
print(X)male、femaleが0と1となり、「カテゴリ変数」と呼ばれるものに変化しています。機械学習に訓練させるときには、このような処理を前処理で行います。
Pclass SibSp Parch Sex_female Sex_male
0 3 1 0 0 1
1 1 1 0 1 0
2 3 0 0 1 0
3 1 1 0 1 0
4 3 0 0 0 1
.. ... ... ... ... ...
886 2 0 0 0 1
887 1 0 0 1 0
888 3 1 2 1 0
889 1 0 0 0 1
890 3 0 0 0 1
[891 rows x 5 columns]同様に、テストデータも同じようにデータ前処理を行っておきます。
X_test = pd.get_dummies(test_data[features])これで、データが整いました。
・y:訓練データの答え(教師データ)
・X:訓練データ
・X_test:予測に利用するデータ。この予測結果をKaggleに提出する。
それでは、ランダムフォレストを訓練させます。
model = RandomForestClassifier(n_estimators=100, max_depth=5, random_state=1).fit(X,y)次に、「X_test」で予測データを作成します。
predictions = model.predict(X_test)最後に、作成したテストデータに対する予測値をテストデータの乗客IDと合わせます。DataFrameで1列目が乗客ID、2列目が予測値という表を作成します。
output = pd.DataFrame({'PassengerId': test_data.PassengerId, 'Survived': predictions})
output.to_csv('my_submission.csv', index=False)
print("Your submission was successfully saved!")output.to_csvという関数で、「my_submission.csv」というファイルを出力します。Notebookの右のData、outputに出力されます。
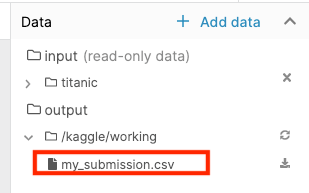
Notebookの出力をKagglenに提出
回答データが出力できたら、右上の「SaveVersion」を押します。
次のようにして、名前をつけて、Notebookのバージョンを保存します。
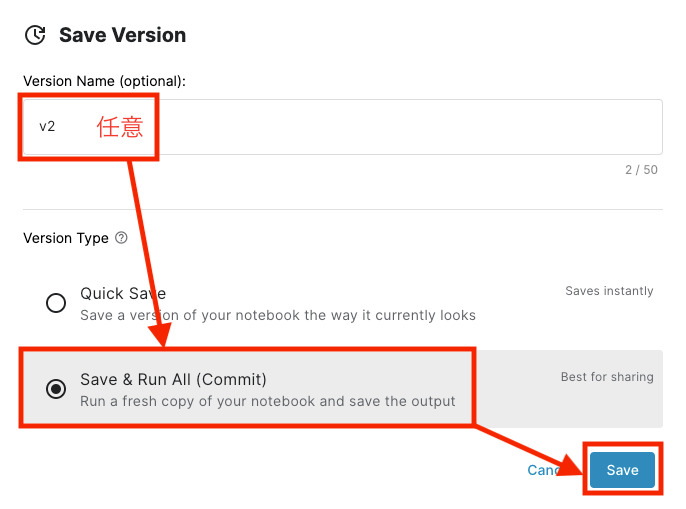
少しだけ作成処理に時間がかかります。
作成が完了すると、存在しているバージョンの数が「SaveVersion」ボタンの右側に出現しますので、ここをクリックします。

そして、画面右の作成したバージョンの詳細をみると、「Open in Viewer」があるのでこれをクリックします。
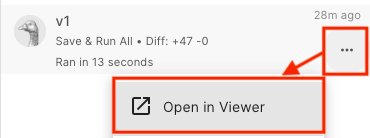
そして、下の図のように、outputの項目をクリックすると「Submit」というボタンが出てきます。
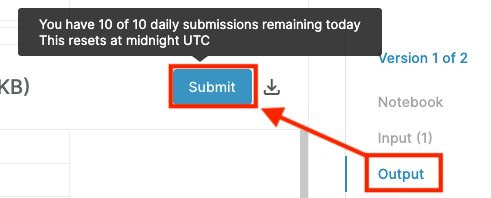
これで、提出できました。
これを目標に順位をアップさせるのは意外と面白いかも。