
kaggleを色々触ってみました。
データの提出とか、Notebookでプログラミングとか、色々便利だよね。
Kaggle内にある、初めて機械学習コンペを始めて、回答を提出するまでの流れが、丁寧にチュートリアルになっていましたので、やってみました。とても親切設計です。随時コンペも開催されていて、上位には賞金も出ますので、入賞できるかは別として、やってみても面白いかもしれません。
今回行うのは、「Titanic Tutorial」というKaggle内の記事を元にしています。
この記事は、Kaggleの上部の検索で「Titanic Tutorial」と入力することで発見することが出来ます。↓

前回のKaggleに登録するところの流れは、こちらの記事もご参照ください。

初めてのデータ提出
タイタニック号の生存予測問題は、最初から答えデータの例が準備されています。それが、「gender_submission.csv」というファイルです。
このファイルは、極端な回答になっています。女性が全員生き残り、男性が全員死ぬという結果としたデータになっています。
まずは、このデータをダウンロードして、Kaggleに提出してみます。
「Compete」から、「Titanic:・・・」を選択すると、タイタニック号に関するデータなどをダウンロードすることが出来ます。データは、「Data」タブからダウンロード可能です。
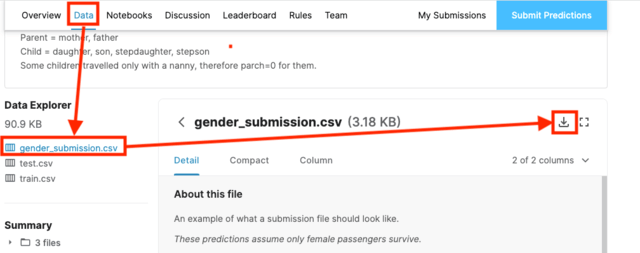
上の図のように、「gender_submission.csv」をダウンロードすることが出来ます。
チュートリアルでは、まずはこの「gender_submission.csv」をKaggleに提出するところから始まります。
「Submit Predictions」からデータ提出画面にうつります。
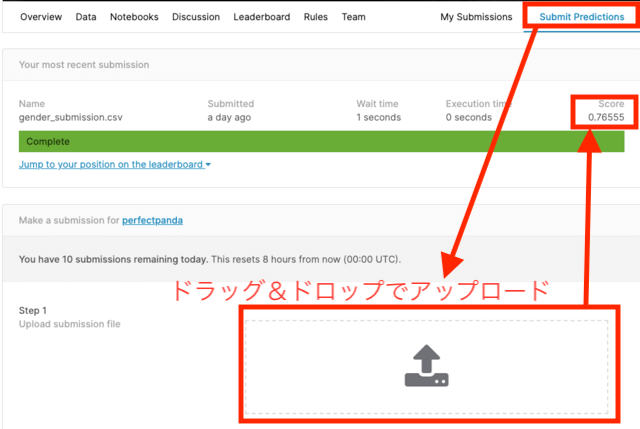
上の図のように、ダウンロードした「gender_submission.csv」をドラッグアンドドロップでアップロードします。
アップロードが完了すると、回答データの正答率が「score」として表示されます。
このスコアを基準にして、上回るようなモデルを目標としてプログラミングに取り組むことになります。
単純な回答で76%になるんだ・・・
KaggleのNotebookでプログラミング
Kaggleの無料のNotebookは、ディープラーニングなどを行うときも、無料のGPUリソースを提供してくれるとのことです。
積極的に使っていきたいと思います。
KaggleへのNotebookのアクセス方法、hello world、タイタニックのデータをNotebookに読み込む方法については、前回の記事をご参考ください。
下準備として、タイタニック号のデータをNotebookに読み込んでおく必要があります。
kaggleのNotebookを開くと、以下のようにnumpyとpandasをimportするブロックが存在しています。コメントを削除して、実行しておきました。
import numpy as np # linear algebra
import pandas as pd # data processing, CSV file I/O (e.g. pd.read_csv)
import os
for dirname, _, filenames in os.walk('/kaggle/input'):
for filename in filenames:
print(os.path.join(dirname, filename))pandasでタイタニック号の訓練データを「train_data」変数に、DataFrameとして読み込んでみましょう。
train_data = pd.read_csv("/kaggle/input/titanic/train.csv")
train_data.head()
今度は、「test.csv」をpandasでみてみます。kaggleのタイタニック号のチュートリアルでは、この「test.csv」に対する正答率を上げていくことになります。
test_data = pd.read_csv("/kaggle/input/titanic/test.csv")
test_data.head()
ここまでで、TitanicTutorialのPart2まで行ったことになります。
今回は、とりあえずPart2までを行いました。Part3では、ランダムフォレストによるプログラミングに入っていきます。次回は、プログラミングに関する部分を翻訳??実践した部分を記事にできればと思います。
なんだか、チュートリアルの日本語訳みたいになってしまいましたが、kaggleを始めてみよう、と思っていたけれど、英語を読むのがめんどくさい、なんとなくそっとウィンドウを閉じてしまった、という人の一助になればと思います。