
なかなかスコアを上げていくのは難しいんだね
そんなに簡単ではないでしょう、もっと勉強しなさい
Kaggleのタイタニックのチュートリアルで、スコアを上げるために奮闘しておりました。データの前処理として特徴量を増やしたり、Nanという欠損値を取り除いたりして試したりしました。結局、データの前処理をいくつか試してみましたが、スコア77%の壁を乗り越えることはできませんでした^^;
今回は、こうやったけれど微妙でしたという羅列となりますので、ご了承くださいm__m
前回の多層パーセプトロンでのタイタニック問題については、こちらの記事もご参考ください。

データの前処理という方向性
前回は、タイタニックデータに対して、scikit-learnのMLPをoptunaによるハイパーパラメータ探索で77%という結果になりました。以前、乳がんデータの分類で、MLPを利用した時は、データの標準化などの前処理を行うことでかなりスコアが改善されましたので、色々とタイタニックデータを前処理する方法を模索したりしていました。
タイタニックデータのセットアップ
KaggleのNotebookにて、csvデータを読み込む部分を以下のようなブロックにまとめました。
#Kaggleノートへのタイタニックのデータのセットアップ
import numpy as np # linear algebra
import pandas as pd # data processing, CSV file I/O (e.g. pd.read_csv)
import os
for dirname, _, filenames in os.walk('/kaggle/input'):
for filename in filenames:
print(os.path.join(dirname, filename))
#csvから訓練データとテストデータを読み込む(pandas)
train_data = pd.read_csv("/kaggle/input/titanic/train.csv")
test_data = pd.read_csv("/kaggle/input/titanic/test.csv")
print(train_data)もちろん、次のようにして、データの中身も確認してみます。
train_data.head()scikit-learnのトイデータのように、答えデータが分離されているわけではなく、「Suvived」という答え項目がまだこのデータに含まれていることには注意しておきます。

train_data.shape891行、12列のデータとなっています。
(891, 12)欠損値の処理
今まで、scikit-learnで勉強している時は、主にnumpyでデータ処理を行ってきましたが、今回はPandasを利用して処理を行いました。
Pandasでは、「.isnull()」という機能で「Nan」という欠損値を調べることができます。また、そのNanの個数を列ごとに「.sum()」で集計することができます。
train_data.isnull().sum()列に対する欠損値をこのようにして調べることができます。
PassengerId 0
Survived 0
Pclass 0
Name 0
Sex 0
Age 177
SibSp 0
Parch 0
Ticket 0
Fare 0
Cabin 687
Embarked 2
dtype: int64今回の方向性としては、「Age」の欠損値は891個中、177個なので、データ自体を削除する方向性にしてみます。また、Cabinの列に関しては、かなりのデータ数が欠損しているので、列自体を削除します。
①Age:Nanの行を削除する対応
②Embarked:Nanの行を削除する対応
③Cabin:列自体をデータから削除
また、データの特性上、利用しないほうが良い列も列自体を削除することにしました。
④PassengerId:生存の可能性にはあまり関係がないと判断しました。(実際にはあるかもしれませんが・・・)
⑤Name:名前も生存の可能性にはあまり関係がないと私が判断しました。
⑥Ticket:チケットの番号についても、生存の可能性にはあまり関係がないと私が判断しました。
というとで、次のようにPandasを利用して、上述した③〜⑥の列をtrain_dataから取り除きました。
train_data_2 = train_data.drop(['PassengerId','Cabin','Name','Ticket'],axis="columns")「drop」という機能は列を削除する機能です。そして、「train_data_2」という変数に格納しました。
データを表形式で確認します。
train_data_2.head()ちゃんと列が取り除かれました。
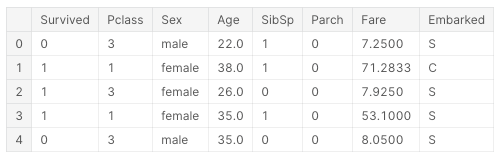
これで、欠損値が多い「Cabin」と必要ないと考えた列がなくなりましたので、「Age」と「Embarked」のNanをもつデータ行を削除していきます。
次のように、train_data_3にNanの行を削除したデータを格納します。
train_data_3 = train_data_2.dropna(axis=0)
print(train_data_3.shape)
train_data_3.head()Nanの行が取り除かれ、712行のデータ、8列のデータとなりました。
(712, 8)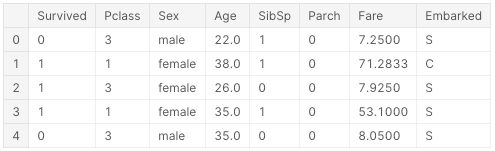
答えデータを分離
ここでやっと、行数が確定しましたので、答えデータとして「Suvived」列を「y」に分離したいと思います。
#答えデータの作成
y = train_data_3["Survived"]
y.shape712行、1列のデータができました。
(712,)性別データをワンホット表現に
最後に、「sex」と「Embarked」の列を、言葉から、数値に表現の変更をします。
まずは、featuresで「Suvived」を除いた列を指定しておき、「Suvived」列がないデータとして「train_data_4」を作成します。
train_data_4をそのままget_dummiesという機能にかけます。こうすることで、性別が文字から0または1という数値表現に変化させることができます。
features = ["Pclass", "Sex", "Age", "SibSp", "Parch", "Fare", "Embarked"]
#特徴量データの作成
train_data_4 = train_data_3[features]
train_data_4 = pd.get_dummies(train_data_4)
print(train_data_4.shape)
train_data_4.head()赤枠のように、それぞれ該当する所に「1」が入るような表現になります。

テストデータも処理する
テストデータは、Nanの行を削除するわけには行かない(提出データとして認められない)ので、AgeとFareの列にNanがあったデータは、データの平均値で埋めることにしました。
#テストデータの作成
X_test = pd.get_dummies(test_data[features])
X_test.head()
#欠損値の確認
print(X_test.isnull().sum())
#欠損値を平均値で埋める
X_test = X_test.fillna({'Age':X_test['Age'].mean(), 'Fare':X_test['Fare'].mean()})
print(X_test.isnull().sum())結果からのもうひと改善
ここまでを行い、テストデータを作成して前回の3層MLPでスコアを出しました。
その結果、74%という結果になりました・・・・
何もしないほうがよかったかも・・・
ということで思い切って全てのデータに対して標準化を行いました。
#訓練データの標準化
from sklearn.preprocessing import StandardScaler
#StandardScalerの作成
scaler = StandardScaler()
#訓練データをもとに標準化して訓練データを標準化
X = scaler.fit_transform(train_data_4)
X = pd.DataFrame(X)
X.head()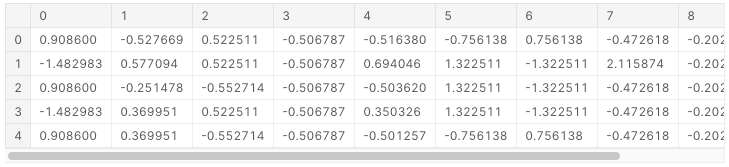
#テストデータの標準化
X_test = scaler.transform(X_test)
X_test = pd.DataFrame(X_test)
X_test.head()色々な数値が標準化されたけれどこれでやってみます。
MLPで評価
ハイパーパラメータはOptunaで検証した結果のものを利用しました。Optunaでのハイパーパラメータ探索は、前回の記事と同じプログラムを利用していますので、今回は取得したパラメータで訓練させるところのみを記載します。
model = MLPClassifier(max_iter=10000,early_stopping=True,hidden_layer_sizes=[136,160,82],learning_rate_init=0.017505133585609213,
solver='adam',activation='relu').fit(X,y)
predictions = model.predict(X_test)そして、最後に「my_submission.csv」として評価データを出力します。
output = pd.DataFrame({'PassengerId': test_data.PassengerId, 'Survived': predictions})
output.to_csv('my_submission.csv', index=False)
print("Your submission was successfully saved!")この結果、77.033というスコアに復活しました。
今回は色々行なった結果、最高スコアを上回ることができませんでしたが、また時間のあるときに挑戦して、実務的なアルゴリズムチューニングのノウハウを得ていきたいと思います。
他にも、サポートベクターマシンや、勾配ブースティングなどのアルゴリズムを試してみるのも良いのかなと考えています。