
計算用を減らす方法の一つを学びました。
できるだけ軽いアプリを作りたいよね~
JUCEチュートリアルのSynth項目、「Control audio levels」の「A minor optimisation」を進めていきます。すごく微小な変更ということですが、音声処理の演算の工夫をして計算量を減らすという点について書かれています。
チュートリアルのページはこちらとなります。

こんな人の役に立つかも
・JUCEフレームワークに入門したい人
・JUCEで音声プログラミングを学びたい人
・JUCEのSynthチュートリアルを進めている人
音声処理部分の変更点
音声処理部分(DSP)の処理関数であるgetNextAudioBlock関数を次のように変更しました。
void getNextAudioBlock (const juce::AudioSourceChannelInfo& bufferToFill) override
{
auto level = (float) levelSlider.getValue();
/*
for (auto channel = 0; channel < bufferToFill.buffer->getNumChannels(); ++channel)
{
auto* buffer = bufferToFill.buffer->getWritePointer (channel, bufferToFill.startSample);
for (auto sample = 0; sample < bufferToFill.numSamples; ++sample)
{
auto noise = random.nextFloat() * 2.0f - 1.0f;
buffer[sample] = noise * level;
}
}
*/
//上コメントアウトした部分のプログラムを↓のように変更しています。
auto levelScale = level * 2.0f;
//[1]
for (auto channel = 0; channel < bufferToFill.buffer->getNumChannels(); ++channel)
{
auto* buffer = bufferToFill.buffer->getWritePointer (channel, bufferToFill.startSample);
for (auto sample = 0; sample < bufferToFill.numSamples; ++sample)
buffer[sample] = random.nextFloat() * levelScale - level;
//[2]
}
}この2つのプログラムは全く同じ動作をしますが、変更後のプログラムのほうが音声データである「buffer[sample]」に対するデータの計算に、掛け算が一つ少ないことがわかります。
[2]の処理では、すでにバッファーのサンプル回数分のループないですので、ここでの計算はサンプル数分繰り返されることになります。そのため、一つでも演算を少なくすることが効率の良い(CPUリソースなどを使わない)DSP処理を考えることにつながります。
今回、[1]のように、2を掛ける演算をあらかじめスライダーから取得した値にかけることで、変更前と同様の結果を得ることができます。
確かに、この方が掛け算が少なくなりますね。512サンプルのバッファーだと512回の掛け算を省略できますね。
今回の演算
今までは、最終的にスライダーの値を掛けることで、-0.25~0.25という値の範囲にスケーリングしていました。今回の方法は、あらかじめスケーリングする値(スライダーの値)を計算することで、オーディオバッファに対する計算量を減らす、という方向性の処理となっています。
出てくる値は次の通りです。
スライダーのとる値:0.0~0.25
random.nextFloatで得られる値:0.0~1.0
まずは、スライダーの値を2倍した値を「levelScale」として計算しておきます。
「levelScale」と「level」変数はそれぞれ2倍の関係になっている点がポイントです。
この2つの変数があれば、音声信号データのサンプルそれぞれに、「levelScale」をかけて「level」を引き算することで、次の図のように、すべてのサンプルに対して、中心を0にして最小値を-0.25、最大値を0.25とすることができます。
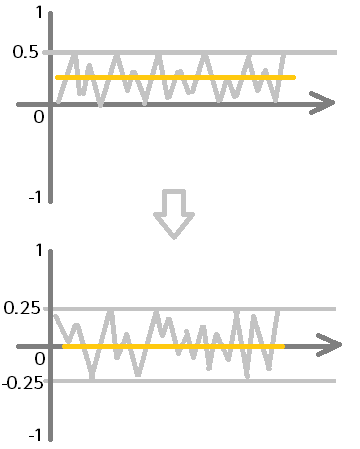
例えば、スライダー値が0.25のとき、nextFloatで得られる値(サンプルの値0~1)がそれぞれ最大、中間、最小のときはこのようになります。
サンプルの値が0.0のとき
levelScaleの値:0.25×2=0.5
サンプルの値:0.0×0.5-0.25=-0.25
サンプルの値が0.5のとき
levelScaleの値:0.25×2=0.5
サンプルの値:0.5×0.5-0.25=0
サンプルの値が1.0のとき
levelScaleの値:0.25×2=0.5
サンプルの値:1.0×0.5-0.25=0.25
音量のスケーリングをするときは、あらかじめスケールに対して2倍して、1倍の値を引く、という処理をサンプルにすることで、計算量が減らせるんですね。