
DCGANのチュートリアルは、訓練データ量がおおので、プログラム実行までのハードルが少し高いかもです。
データの扱いで苦労したような雰囲気・・・
PyTorchのDCGANチュートリアルを進めています。今回一番苦労しているのが、プログラムの実行環境の模索でした。
前回の記事はこちらをご参考ください。

プログラムの実行環境について
DCGANのプログラムを稼働させるにあたり、チュートリアルとして次のような難しさを感じました。
①訓練画像データが1.4Gある
②訓練に時間がかかる
初学者がチュートリアルとして行うには結構なハードルだと思いましたので、この点についていくつか気づいたことをメモしておきます。
訓練データ量について
GoogleColaboでデータにアクセスするためにGoogleDriveにアップロードしてみました。結果として、原因は究明していないのですが、プログラムから画像を読み込みに行くことができず、断念している状態です。また、GoogleDriveにアップロード(実際はzipをコピーして、ZipExtractorというWebサービスでDriveに直接解凍)するだけでも、約40時間がかかりましたので、あまり現実的ではないことがわかりました。
ということで、ローカル環境にダウンロードしてきて、Anaconda環境のJupyterNotebookで検証するというやり方が現実的でした。
訓練時間
ローカル環境では、macでの実行とGPUを搭載したWindowsで試しました。
macのローカル環境
macでは、基本的にNVIDIAのGPUが利用できないので(頑張れば使えるようですが)、CUDAを利用できないことになります。mac mini2018はそこそこ上位の「i7-8700B」というCPUを搭載しています。プログラムの訓練を実行して、1時間くらい実行した後、諦めました 笑
訓練では、1エポックあたり1583のバッチを処理します。全データ訓練までに20.3万枚のデータを1583のミニバッチに分けて訓練を行います。50ミニバッチ毎に進捗状況が表示されるようになっています。CPU処理のみですと、これが途方もない雰囲気が出ていました。
Windowsのローカル環境
Windowsのマシンのスペックは、以下の環境でためしました。
CPUはmac mini2018と同じラインナップです。偶然にも、NVIDIAを搭載していました 笑
DellのXPSというワークステーションタイプのとてもコスパが良いPCです。
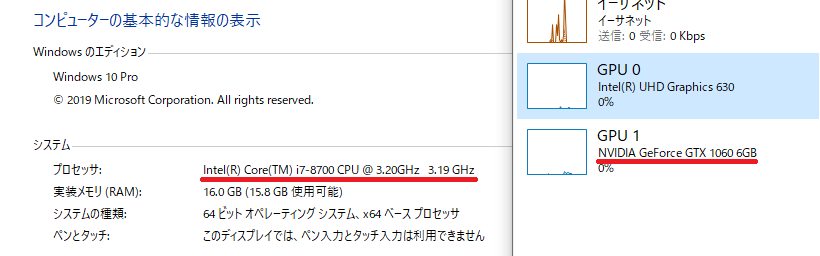
このスペックでDCGANの訓練を行うと、1エポックあたり約7分で終了します。チュートリアルの5エポックでは、約30分程度でした。
GPU恐るべし・・・
DCGANのチュートリアルを行うにあたって、NVIDIAのGPUを利用しないと時間がとてもかかることがわかりました。AppleはNVIDIAを利用しない方向性らしいので、CUDAを簡単に利用していくとすると、Windowsマシンでスペックの良いGPU(ノートPC+eGPUなどでも可能かもしれません。)で拡張するのが良いのかもしれません。
DCGANの訓練
ということで、引き続きチュートリアルのプログラムの勉強を続けます。
誤差と最適化手法の定義が完了している状態です。
次のプログラムで訓練を行います。1エポック20.3万枚の画像になり、1ミニバッチ当り128枚の画像です。
#訓練ループ
#進捗状況を保存するリストと変数
img_list = []
G_losses = []
D_losses = []
iters = 0
print("Starting Training Loop...")
#エポックのループ
for epoch in range(num_epochs):
#ミニバッチのループ
for i, data in enumerate(dataloader, 0):
############################
# (1) ディスクリミネータの訓練: maximize log(D(x)) + log(1 - D(G(z)))
###########################
##本物画像データでの訓練
netD.zero_grad()
#バッチのフォーマット
real_cpu = data[0].to(device)
b_size = real_cpu.size(0)
label = torch.full((b_size,), real_label, device=device)
#本物画像データをディスクリミネータに順伝播させる
output = netD(real_cpu).view(-1)
#本物画像データとの誤差を算出
errD_real = criterion(output, label)
#逆伝播で勾配を求める
errD_real.backward()
D_x = output.mean().item()
##偽物画像データでの訓練
#ジェネレータに与える潜在ベクトルの作成
noise = torch.randn(b_size, nz, 1, 1, device=device)
#ジェネレータに潜在ベクトルを入れて偽画像を取得
fake = netG(noise)
#偽画像データに偽のラベル(答え)を付ける
label.fill_(fake_label)
#偽画像をディスクリミネータで予測
output = netD(fake.detach()).view(-1)
#ディスクリミネータ
errD_fake = criterion(output, label)
#偽画像データに対する勾配の計算
errD_fake.backward()
D_G_z1 = output.mean().item()
#勾配の計算と、重みの更新
#本物画像データと偽物画像データから得た誤差を加算
errD = errD_real + errD_fake
#ディスクリミネータの重みを更新
optimizerD.step()
############################
# (2) ジェネレータの訓練: maximize log(D(G(z)))
###########################
netG.zero_grad()
label.fill_(real_label) # fake labels are real for generator cost
#Dは更新済みなので、Gが生成した画像をDまで順伝播させて出力を得る。
output = netD(fake).view(-1)
#ジェネレータの誤差を求める
errG = criterion(output, label)
#逆伝播で勾配を求める
errG.backward()
D_G_z2 = output.mean().item()
#重みを更新する。
optimizerG.step()
#訓練の進捗を表示するための処理
if i % 50 == 0:
print('[%d/%d][%d/%d]\tLoss_D: %.4f\tLoss_G: %.4f\tD(x): %.4f\tD(G(z)): %.4f / %.4f'
% (epoch, num_epochs, i, len(dataloader),
errD.item(), errG.item(), D_x, D_G_z1, D_G_z2))
#グラフのプロット用にデータを保存しておく
G_losses.append(errG.item())
D_losses.append(errD.item())
# Check how the generator is doing by saving G's output on fixed_noise
if (iters % 500 == 0) or ((epoch == num_epochs-1) and (i == len(dataloader)-1)):
with torch.no_grad():
fake = netG(fixed_noise).detach().cpu()
img_list.append(vutils.make_grid(fake, padding=2, normalize=True))
iters += 1訓練は、「(1)ディスクリミネータ」→「(2)ジェネレータ」の順番で行われます。
(1)で、ディスクリミネータに本物を本物と判定させられるように本物画像、偽物画像を順番に入れて訓練します。
(2)で、訓練されたディスクリミネータに対してジェネレータが自分の作成した偽画像を本物といわせるように訓練します。ここでは、出力はディスクリミネータの出力を利用します。このディスクリミネータまでの出力に対して、生成する画像が本物と判定されるように重みを更新します。
そして、次のバッチになります。
訓練は、0~4までの5エポック実行されます。最後の表示は以下のようになります。(最初、5回目実行されずにおわっている、と思いました・・・ので、表示用に+1しておいた方が間違えなくて良いかもしれません。)
...省略...
[4/5][1500/1583] Loss_D: 0.5098 Loss_G: 1.8800 D(x): 0.6812 D(G(z)): 0.0693 / 0.1944
[4/5][1550/1583] Loss_D: 1.2030 Loss_G: 5.2298 D(x): 0.9598 D(G(z)): 0.6432 / 0.0095次のプログラムは、ジェネレータとディスクリミネータの損失をグラフとしてプロットします。回数を重ねるごとにDとG両方の損失が低下していっています。
plt.figure(figsize=(10,5))
plt.title("Generator and Discriminator Loss During Training")
plt.plot(G_losses,label="G")
plt.plot(D_losses,label="D")
plt.xlabel("iterations")
plt.ylabel("Loss")
plt.legend()
plt.show()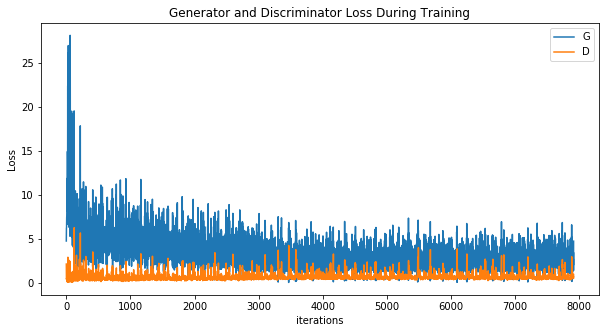
次のプログラムで、一定間隔毎の生成画像を確認することができます。
#%%capture
fig = plt.figure(figsize=(8,8))
plt.axis("off")
ims = [[plt.imshow(np.transpose(i,(1,2,0)), animated=True)] for i in img_list]
ani = animation.ArtistAnimation(fig, ims, interval=1000, repeat_delay=1000, blit=True)
HTML(ani.to_jshtml())


最後に、偽画像と本物画像を比較するプログラムです。
# Grab a batch of real images from the dataloader
real_batch = next(iter(dataloader))
# Plot the real images
plt.figure(figsize=(15,15))
plt.subplot(1,2,1)
plt.axis("off")
plt.title("Real Images")
plt.imshow(np.transpose(vutils.make_grid(real_batch[0].to(device)[:64], padding=5, normalize=True).cpu(),(1,2,0)))
# Plot the fake images from the last epoch
plt.subplot(1,2,2)
plt.axis("off")
plt.title("Fake Images")
plt.imshow(np.transpose(img_list[-1],(1,2,0)))
plt.show()
なんとか完了しました。