
digitという手書き文字のデータがあって、それを分類してみたい。
初めての画像系だね!
scikit-learnの中に、digitという手書き文字の分類があるそうです。今までは、数値データに対する分類を行ってきましたが、画像となると少し面白そうな雰囲気がします。結局は数値データなんですが、画像の数値としての捉え方など、色々勉強になります。ということで、まずはデータについて知るところからです。
こんな人の役に立つかも
・機械学習プログラミングを勉強している人
・digitの手書きデータの分類の勉強をしている人
・digitのデータの構造が知りたい人
Digitについて
色々な人が書いた0~9までの手書き数字のデータです。
「手書きの0~9までの数字を分類することを目標」に訓練させます。
digitデータは、scikit-learnの公式サイトの解説によると、
・10クラス分類
答えとなるデータの種類が手書き文字0〜9の10種類
・一つのクラスに180個までのデータがあるよ
・サンプルは全部で1797個あるよ
・特徴量は64次元だよ
・特徴は0〜16の整数をとるよ
とのことでした。公式サイトの解説ページはこちら↓

データをグラフにしてみるとこのような感じになりますね。
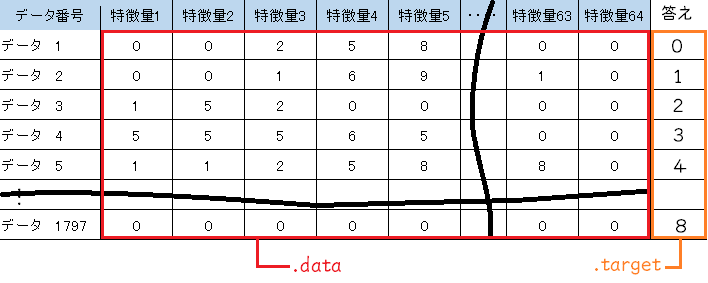
64次元って・・・どんな領域??
Digitがどんなデータかプログラムでみてみよう
以下のコードでimportして、load_digits()をすることで読み込むことができます。
digiという変数にdigitデータを入れています。
from sklearn import datasets
digi = datasets.load_digits()アヤメデータなど、他のscikit-learnデータと同じように、「.data」に64個の特徴量のデータが、「.target」に答えデータが入っていますので、次のようにして読み込みます。
X = digi.data
print(X.shape)
Y = digi.target
print(Y.shape)データ数が1797個、特徴量が64次元あることがわかりますね。また、対応する答えデータも1797個存在していることがわかります。
(1797, 64)
(1797,)64個の特徴量は何を示しているのか?
今回のdigitデータには、アヤメのデータなどのように「feature_names」で特徴量のラベルをみることができませんでした。
公式サイトにはあるはずなんですが、
print(digi.feature_names)このようにしても、特徴量のラベルが返ってくることはありませんでした。
64個の特徴量は次の図のようなイメージです。
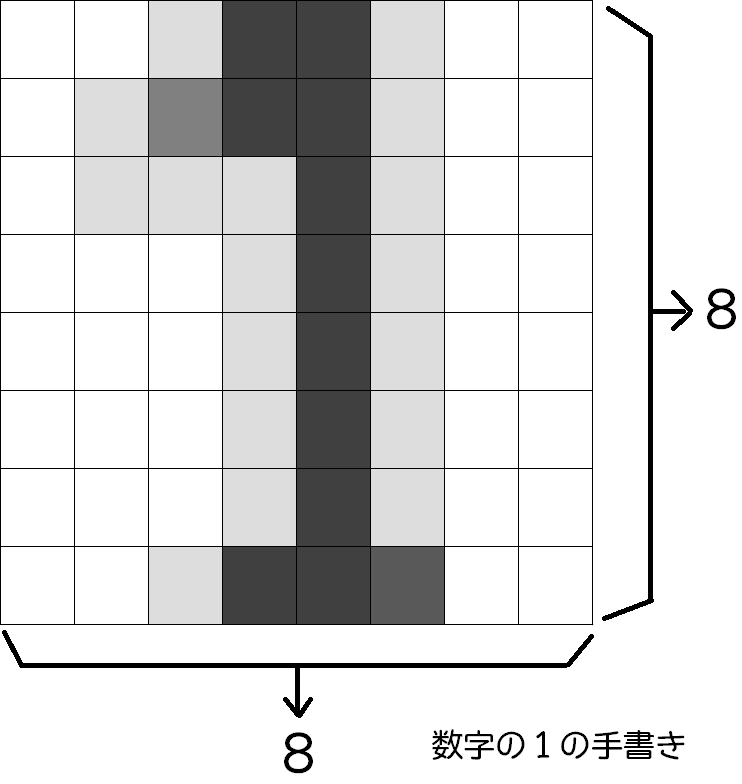
8×8のピクセル画像を思い浮かべるとわかりやすいです。このピクセルを左上から右に8個、次に2行目が8個・・・8行目までの8個というように配列にすると64個のピクセルが横並びになります。この一つ一つにピクセルがdigitデータにおける特徴量になります。
digitデータには、この8×8(64個の特徴量)のデータが1797個存在します。
やたら次元が多いと思っていたけど、こういうことか・・・
そして、ピクセル一つ一つが取っている値でそのピクセルの濃度を16段階に分けます。次のようなイメージです。

このような感じであるピクセルの濃度がどのようになっているかでアルゴリズムを訓練させるようです。
digitデータには、imagesというデータがあります。これは、dataの元となった画像データになります。試しにshapeしてみます。
print(digi.images.shape)imagesは、3次元のデータです。8×8の縦横の表データを1797個持っているようなイメージでしょうか。
(1797, 8, 8)試しに、一つ目の数字画像データをみてみます。
print(digi.images[0, :, :])なんだか数字っぽいような表です。
[[ 0. 0. 5. 13. 9. 1. 0. 0.]
[ 0. 0. 13. 15. 10. 15. 5. 0.]
[ 0. 3. 15. 2. 0. 11. 8. 0.]
[ 0. 4. 12. 0. 0. 8. 8. 0.]
[ 0. 5. 8. 0. 0. 9. 8. 0.]
[ 0. 4. 11. 0. 1. 12. 7. 0.]
[ 0. 2. 14. 5. 10. 12. 0. 0.]
[ 0. 0. 6. 13. 10. 0. 0. 0.]]matplotlibで濃度ありの表示をしてみます。
import matplotlib.pyplot as plt
plt.gray()
plt.matshow(digi.images[0, :, :])
plt.show() 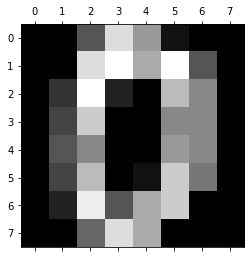
0だったのか・・・
まとめ
digitで、画像をデータとしてどのように扱うのか、が少しだけわかったような気もします。一部、データの公式の説明で実際に動かない(feature_names)点もありましたが、私の理解不足なのかもしれません。大枠は理解できたということで今回はこの辺りにしたいと思います。