
scikit-learnのパラメータ調整で、max_leaf_nodesは重要っぽい
重要なパラメータが何かを知っておいたほうがいいね
前回までの決定木のパラメータmax_depthは、重要でした。今回は、scikit-learnの決定木でチューニングできるたくさんのパラメータのうち、max_leaf_nodesというパラメータに焦点を当てて、チューニングを行ってみました。
前回の決定木の記事についてはこちらもご参考ください。

こんな人の役に立つかも
・機械学習プログラミングを勉強している人
・scikit-learnの決定木を勉強している人
・scikit-kearnの決定木、max_leaf_nodesの調整をしている人
max_depthのみの調整プログラム
前回のmax_depthのみの調整の時には、テストデータへの精度のみみていました。訓練データへの精度が抜けておりまして・・・
max_depth=4とした時の決定木のプログラムを掲載します。
from sklearn.datasets import load_breast_cancer
from sklearn.model_selection import train_test_split
#from sklearn.model_selection import cross_val_score
from sklearn import tree
import matplotlib.pyplot as plt
import numpy as np
#乳がんデータ
panda_box = load_breast_cancer()
#2個分の特徴量に絞る
X = panda_box.data[:,0:2]
#X = panda_box.data
y = panda_box.target
#訓練データとテストデータに分割
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size = 0.25, stratify=y, random_state=0)#決定木
clf = tree.DecisionTreeClassifier(max_depth=4).fit(X_train,y_train)
print("訓練データへの精度")
print("{:.4f}" .format(clf.score(X_train, y_train)))
print("未知データへの精度")
print("{:.4f}" .format(clf.score(X_test, y_test)))訓練データへの精度
0.9343
未知データへの精度
0.8881
一部、明らかに過学習したような境界線があるのがわかります。max_depthのみの調整の場合、まだ不十分感が否めません。
ここで、max_leaf_nodesというパラメータを調整することにしました。
max_leaf_nodes
max_leaf_nodesを調整すると、葉っぱの数で木構造を調整することができます。作成される「葉」は、「不純度」という数値を計算して作成されるかどうかが判定されます。
決定木の木構造で条件がないものが「葉」になります。不純度が大きい順に「葉」を作成して、最大の値になるまで「葉」を増やす仕組みです。
「不純度」は決定木の作成過程をなんやかんやで計算される、データの答えが違うものが混ざっている度合いみたいなイメージでしょうか。混ざっている答えデータが多い方の範囲をさらに細分化を優先するみたいな感じでしょうね。
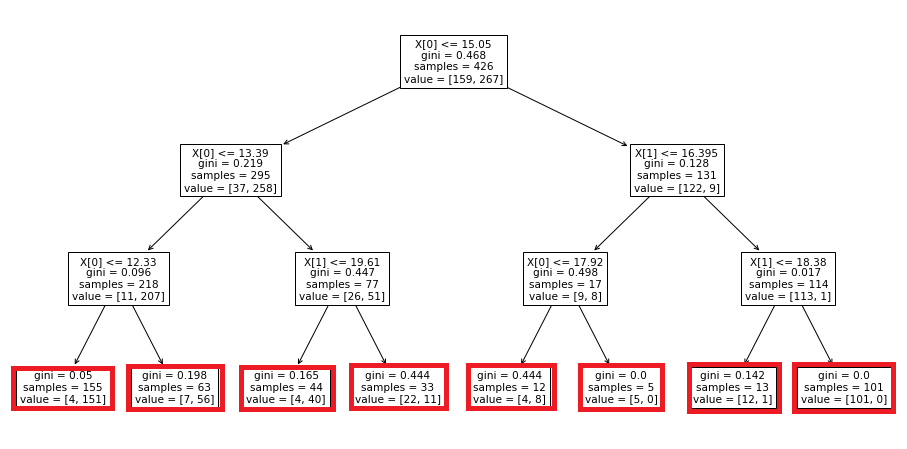
max_leaf_nodesの調整
max_leaf_nodesは、次のようにパラメータで指定することで調整できます。
DecisionTreeClassifier(max_leaf_nodes=3)次に作成したのは、このmax_leaf_nodesを増加させて、一番良い精度がでるパラメータを確認するプログラムです。
このプログラムで、一度に max_leaf_nodesの値を変化させた時の訓練データへの精度、テストデータへの精度がわかります。今回は、「2〜6」までの時をみてみました。
※max_leaf_nodesは2以上の数値出ないといけない。
train_dat_array = []
test_dat_array = []
for i in range(5):
#決定木
clf = tree.DecisionTreeClassifier(max_leaf_nodes=i+2).fit(X_train,y_train)
train_dat_array.append(clf.score(X_train, y_train))
test_dat_array.append(clf.score(X_test, y_test))
print(train_dat_array)
print(test_dat_array)最初に、訓練データへの精度を保存するリスト「train_dat_array」と、テストデータへの精度を保存するリスト「test_dat_array」を用意します。
次に、for文で5回、決定木のパラメータを切り替えながら評価します。評価された訓練データとテストデータは、appendというリストの最後にデータを追加する機能で追加されていきます。
最後に、5回分の訓練データとテストデータの配列を表示しています。
リストの内容をmatplotlibでグラフ化してみやすくしてみます。
import matplotlib.pyplot as plt
import numpy as np
X_axis = np.linspace(2,6,5)
#print(X_axis)
plt.plot(X_axis, train_dat_array)
plt.plot(X_axis, test_dat_array)青色が訓練データへの精度、オレンジがテストデータへの精度になります。
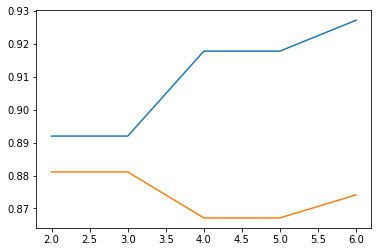
max_leaf_nodesが4になったときに、訓練データへの精度が上昇して、テストデータへの精度が低下しています。ここで過学習が起きていることがわかります。
今回は、「3」をパラメータとして設定しておくことにします。
次のようにして、「max_leaf_nodes=3」の時の境界線を確認してみます。
clf = tree.DecisionTreeClassifier(max_leaf_nodes=3).fit(X_train,y_train)
#決定木のグラフ
fig = plt.figure(figsize=(8, 8))
ax = fig.add_subplot(111)
#グリッドのデータを作成
X0 , X1 = X_train[:,0], X_train[:,1]
xx, yy = make_meshgrid(X0, X1)
#グラフに境界線とデータをプロット
plot_contours(ax, clf, xx, yy, cmap=plt.cm.coolwarm, alpha=0.8)
ax.scatter(X0, X1, c=y_train, cmap=plt.cm.coolwarm, s=20, edgecolors='k')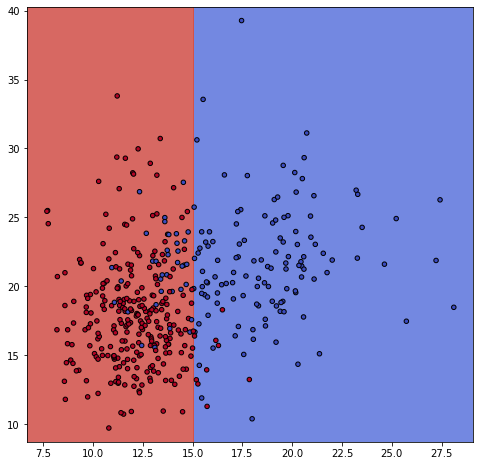
シンプルイズベスト!
なんだかんだチューニングを頑張ると、シンプルになりました。
ただ、max_depthの時は、布の断線みたいなところがあったので、こちらの方がテストデータへの精度も同じくらいでちょうどいい感じの境界線となった気がしています。
#決定木の中身を確認
#matplotlibで描画領域の作成
fig_dt = plt.figure(figsize=(16,8))
ax_dt = fig_dt.add_subplot(111)
#木構造を出力
tree.plot_tree(clf, fontsize=10.5, ax = ax_dt)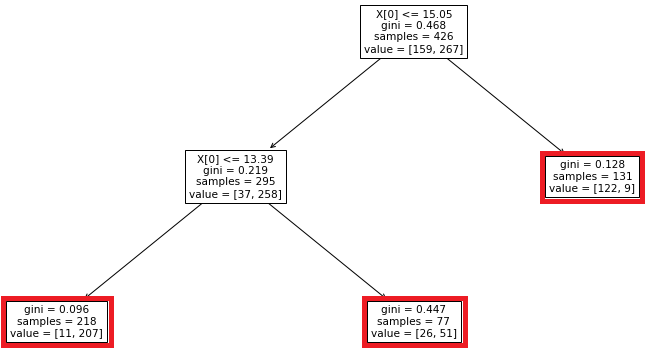
赤枠のところが今回の決定木の葉になります。
いい感じにシンプルになっているような・・・