
ConfusionMatrixっていうもので、分類問題をもっと詳しく分析できるようになりそうだ。
単純に正解率を出すだけじゃないってことだね。
ConfusionMatrixというものを勉強しました。今までは、scikit-learnの機械学習アルゴリズムに「score」という正解率を出してくれる機能がありましたので、頼り切っていました。単純に正解率を上げるようなチューニングをするより、どこがどのように間違っているのかをより細かく見ることで分析することができます。これをするために、ConfusionMatrixを利用するみたいです。
こんな人の役に立つかも
・機械学習プログラミングを勉強している人
・ConfusionMatrixについて勉強している人
・scikit-learnのConfusionMatrixを利用したい人
ConfusionMatrixってなんだろう
ConfusionMatrixは日本語で「混同行列」と訳されます。
ConfusionMatrixは、「2値」分類問題結果で、より詳細に分析ができる数値を教えてくれます。
※答えデータをPositiveまたはNegativeへ分類する2値問題として話を進めます。
乳がんデータの答えは「0」が悪性、「1」が良性のデータです。
良性は、答えとしてPositiveなので、「1」がPositive、悪性が答えとしてNegativeなので「0」がNegativeとします。ConfusionMatrixにおいて、0と1のどちらがNegativeかPositiveかをしっかり把握しておくことはとても大切です。まずは乳がんデータの場合、
「0」:Negative
「1」:Positive
をしっかりと把握します。
2値というところがポイントだね。
ConfusionMatrixは、今までの単純な正解率ではなく、予測でPに分類された中で「正しくPに分類できた数」と、「間違えてNにした数」を、また同様に予測でNに分類された中で「間違ってPに分類した数」と「正しくNに分類できた数」を出力してくれます。
なんだかややこしいから表にしてみよう。

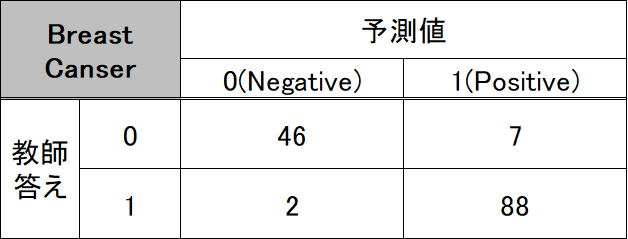
ConfusionMatrixは、このような表を出力してくれます。見方として、予測値を基準に縦に見ると混乱せずに理解できそうです。
表にしてもかなり混乱しました・・・さすがConfusionマトリックス・・・
水色枠はアルゴリズムがNegative(0)と予測しました。しかし、本当の教師データの答えは表の行(横方向)で、それぞれ予測値が0で教師の答えも0は、「Negative」と予測した中で正しい数、また、予測値が0で教師データの答えが本当は1の時は、間違いの数を表示します。オレンジ枠ではPositiveの答えに対して、「Positive」と予測した中で正しい数、間違いの数を表示します。
ConfusionMatrixを試してみる
今までの評価方法に加えてみる
今までは、scikit-learnの機械学習アルゴリズムの「score」機能で下のプログラムのように正解率を出力していました。乳がんデータのロジスティック回帰での分類です。
ロジスティック回帰の分類問題については、こちらの記事もご参考ください。

#ホールドアウトのimport
from sklearn.model_selection import train_test_split,cross_val_score
#乳がんデータ
from sklearn.datasets import load_breast_cancer
#ロジスティック回帰
from sklearn.linear_model import LogisticRegression
panda_box = load_breast_cancer()
X = panda_box.data
y = panda_box.target
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size = 0.25, stratify=y)
#ロジスティック回帰
cls = LogisticRegression(max_iter=10000)
#★訓練~テスト★
cls.fit(X_train,y_train)
print("訓練データの評価")
print("{:.4f}".format(cls.score(X_train, y_train)))
print("テストデータの評価")訓練データの評価
0.9554
テストデータの評価
0.9371ConfusionMatrixを利用するために、次のプログラムを追加します。
from sklearn.metrics import confusion_matrix
predict = cls.predict(X_test)
#ConfusionMatrixの表示
print(confusion_matrix(y_test, predict))confusion_matrixをimportします。
そして、訓練させたロジスティック回帰をテストデータでpredictします。こうすることで、訓練したモデルからテストデータの予測値がリストとしてpredict変数に入ります。
confusion_matrixには、(教師の答え, 予測値)とすることで次のようにConfusionMatrixが出力されます。
[[46 7]
[ 2 88]]この結果を先ほどの図に当てはめてみると、次のようになります。
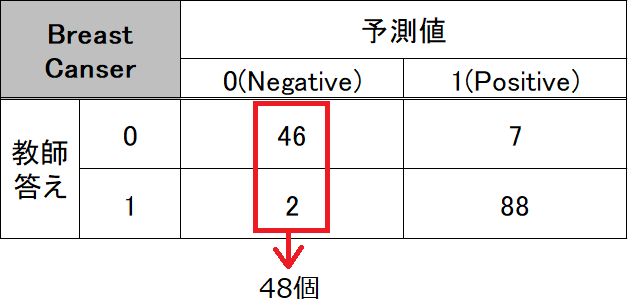
念のため、本当に予測値のNegativeが0かを次のように確認してみます。
print(predict[predict==0].shape[0])predictというアルゴリズムが予測した結果の中の0の数をカウントします。predictのリストの中のpredict==0と指定することで、0のみのデータを抽出します。そして、0のみのリストとなるので、shapeで、そのリストの形を確認します。shapeは、行と列を(行,列)と出力してくれます。今回は1次元のリストなので、行のみしかないことになります。そのため、行の部分(shape[0])を確認することで、predictのなかで0のデータをカウントすることができるのです。
48train_test_splitが違うデータを作成しますので、この数値は実行する毎にかわります。(random_stateを指定しておけば、最初に実行して二回目以降は同じ数値を得られますが、一度実行環境を終了して再度実行すると値は変化します。)
アルゴリズムが予測したpredictの中の0の答えデータは、48個あることがわかりました。
これで、NegativeとPositiveが正しく理解できていると確認することができました。
2値問題では重要な間違いもある
単純な正解率では、正解数(↓図のオレンジと水色の〇)を全体のテストデータとの割合になるので、どのように間違いを起こしているのか、がわかりづらくなります。

乳がんデータの場合、赤枠の、本当は「Negative」、悪性なのに「Positive」、良性と判定する、ということは人の死につながる可能性もありますので、現実で致命的な問題となります。
一方、「Positive」、良性なのに、「Negative」、悪性と判定されたら、がんの再検査で終わります。
ConfusionMatrixでは、どの数を減らして正解率を上げていくのかという方向性を考えることができるようになります。
多クラス問題への応用
今まで、ConfusionMatrixの2値問題への適用を見てきましたが、多クラス問題でつかえないの??という点についても調べてみました。
答えが「0」または「1」ではなくても、応用で答え「0」と「そのほか」のように、2値問題のようにしてConfusionMatrixを作成してくれるみたいです。