
教師なし学習で、今までにPCAを勉強しているけれど、クラスタリングというものもあるみたい。
やっと二つ目の教師なし学習だね。
クラスタリングという教師なし学習について学んでいます。教師なし学習は、機械学習をある程度学んでいないと、どんなものかわかりにくいと感じています。教師あり学習を行う前のデータの前処理などで活躍することが多く、結果が明確にわかるというものも少ないです。教師なし学習は、縁の下の力持ち的なイメージがつきました。
こんな人の役に立つかも
・機械学習プログラミングの勉強をしている人
・クラスタリングを勉強している人
・クラスタリングの概要を知りたい人
クラスタリングの概要
クラスタリングは、データを分類してくれます。しかし、教師あり学習の分類とは違います。
もともと答えがわかっているデータの分類をするのではなく、
「このデータの集合には何かしらの分類ができるか???」
というような時にクラスタリングをすることでそのデータの集まりの分類を発見するような時に見つけます。
教師がない(答えがない)ので、クラスタリングをした結果の分類が本当に正しいのかどうかを評価するすべが難しいという点があります。
k-meansという手法が代表的なアルゴリズムとなります。
scikit-learnでクラスタリング
実際にプログラムでどのように動くのか見ていきたいです。Kmeansがランダムに作成したデータに対してどのように動作するのかをみていきます。
クラスタリングのためのデータを作ろう
import matplotlib.pyplot as plt
import numpy as np
import pandas as pd
#ランダムなデータを生成
myarray1 = np.random.randint(1, 100, 30).reshape(-1,1)
myarray2 = np.random.randint(1, 100, 30).reshape(-1,1)
myarray = np.concatenate([myarray1, myarray2], 1)ランダムなデータを作成するために、numpynのrandintを利用しました。
「np.random.randint(1, 100, 30)」
整数のみにして、0~100までの間の整数で30個のランダムな数値のarrayを作成しています。これを、2特徴量分作成するので、「myarray1」「myarray2」と2回やっています。
また、「.reshape(-1,1)」でarrayが横方向となっているので、縦方向へと変換してあげます。
最後に、2次元(表形式)にするために「myarray1」と「myarray2」を結合しました。
ここで作成したグラフをmatplotlibで見てみます。
#空のグラフを作成
fig = plt.figure(figsize=(5, 5))
ax = fig.add_subplot(111)
#ランダムなデータを可視化
ax.scatter(myarray[: , 0], myarray[: , 1])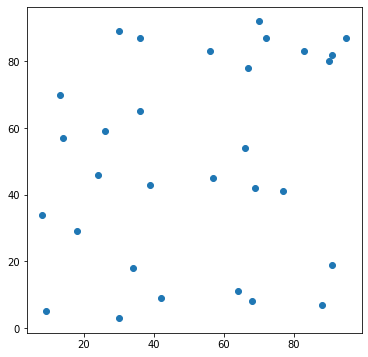
numpyもだいぶ慣れてきた。
クラスタリングをしてみよう
次に、先ほど作成したデータをクラスタリングしてみます。ランダムにバラバラに散らばったデータですが、これをいくつかの塊に分類するとどのようになるでしょうか??
クラスタリングはscikit-learnのclusterのKMeansというものを利用します。
#クラスタリング
from sklearn.cluster import KMeans
kmeans = KMeans(n_clusters = 4)
kmeans.fit(myarray)KMeansを作成するときに、パラメータ「n_clusters」で、何個のクラスターに分けるかを指定します。今回は適当に4としました。
KMeansを実行するには、「.fit」を使います。先ほど作成した「myarray」をクラスタリングするので、kmeans.fit(myarray)となります。
fitすると、「labels_」に分類された答えが入ってきますので、それをのぞいてみます。
#ラベルづけされる。
print(kmeans.labels_)[0 1 3 0 0 0 3 2 3 2 1 3 1 1 2 1 0 3 3 1 3 2 0 2 2 3 0 0 0 2]30個の答えデータが得られました。教師あり学習では、これが正解かどうか答え合わせをするのですが、クラスタリングでは答えがないデータなので、これが本当に良い答えなのかはわかりません。
答えデータをそれぞれのデータの色として変更してみます。シーボーンで綺麗なグラフが描けますので、シーボーンでやってみます。
myarray_pd = pd.DataFrame(myarray)
pd_label = pd.DataFrame(kmeans.labels_)
import seaborn as sns
#表の結合
md = pd.merge(myarray_pd, pd_label, left_index=True, right_index=True)
md.columns = ['random1', 'srandom2', 'label']
#空のグラフを作成
fig2 = plt.figure(figsize=(6, 6))
ax2 = fig.add_subplot(111)
ax2 = sns.scatterplot(data=md,x='random1',y='srandom2',hue='label')シーボーンにするためには、pandasのDataFrameに変更する必要があるので、myarrayを「myarray_pd」、クラスタリングの答えを「pd_label」として変換しています。
また、答えデータも一体の表である必要があるので、myarray_pdとpd_labelを結合しておきます。列名も「columns」で指定します。
シーボーンの表は、matplotlibと同じようにサイズを調整できますので、matplotlibにて表サイズの調整(fig2,ax2)を行った後、シーボーン(sns)でグラフを作成しています。「hue=’label’」と指定することで、4種類の答えデータに対応する色付けされたグラフを描くことができます。
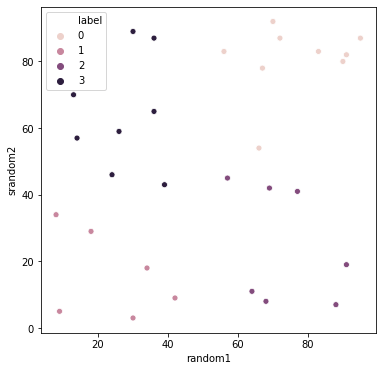
ランダムに作ったはずなんだけどこうしてみるとなんとなく4つのカテゴリに別れている気がする。
今回はデータはランダムな数値だから分ける意味はないんだけどね・・・
ランダムなデータを元にクラスタリングしているので、クラスタリングする意味はない(元々のデータ自体に意味がない)のですが、このようにクラスタリングが教師なしで分類のような動作をしているということがわかりました。
最後に、見比べ用の図を貼り付けます。