
今回は実際に、KerasとTensorFlowでニューラルネットワークの分類モデルを作成しました。
チュートリアルは、ニューラルネットワークだけど、中間層を増やせばディープラーニングになるんだね。
前回確認したFashionMNISTのデータで、実際にモデルを作成して分類課題を行ってみました。
前回の記事はこちらです。

Kerasがあるからか、意外と直感的にscikit-learnのMLPのようにニューラルネットワークが構築できる感触です。今回も、チュートリアルに沿ってプログラムの動作確認をしながら、今まで利用してきたscikit-learnとの違いなどに触れながらやっていきたいと思います。
前回に引き続き、こちらのチュートリアル記事を参考にしています。
こんな人の役に立つかも
・機械学習プログラミングを勉強している人
・Keras+TensorFlowでFashioMNISTチュートリアルをしている人
・Keras+TensorFlowでディープラーニングの勉強を始めたい人
Keras+TensorFlowでの分類問題の流れ
次の流れで分類問題に取り組みます。
1.データの前処理
ニューラルネットワークが訓練しやすい、精度が出るようなデータの形にします。
2.モデルの定義
層の設定を行います。
チュートリアルでは、入力層、中間層、出力層のニューラルネットワークを構築します。
3.モデルのコンパイル
損失関数の方式の設定等を行います。
4.訓練
訓練データから訓練を行います。
5.評価
テストデータへの精度を出します。
基本的にscikit-learnの流れに似ていますね。コンパイルという手順が多い以外はほぼ似たようなものです。
scikit-learnの手順に似ているから余裕かな・・・
チュートリアルプログラミング
データの前処理
0〜255の値を0~1にスケーリングします。
具体的には、「X_train」と「X_test」を255で割ることで、0~255の数値を0~1の間の数値に収めることができます。
ニューラルネットワークは標準化や正規化といったようなスケーリングで数値のばらつきを抑えることが効果的、と以前scikit-learnのMLP(多層パーセプトロン)でも勉強しました。
今回は、すべて画像データのため、あらかじめ最小値が「0」、 最大値が「255」と決まっていますので、単純に255で割るだけで0~1に収まってくれるのでこのような処理になっています。
※Pythonの計算の問題ですが、「255.0」は「.0」をつけてあげることで、小数点の計算となります。
X_train = X_train / 255.0
X_test = X_test / 255.0このプログラムで、画像データの「黒の濃さである数値、0~255の値」を「0~1」にスケーリングしました。
前処理の工程は、データの特性でいろいろと処理を変えていく必要があるね。
画像前処理の一つのパターンを学んだね。
モデルの定義
ここで、ニューラルネットワークの層の部分を定義します。
model = keras.Sequential([
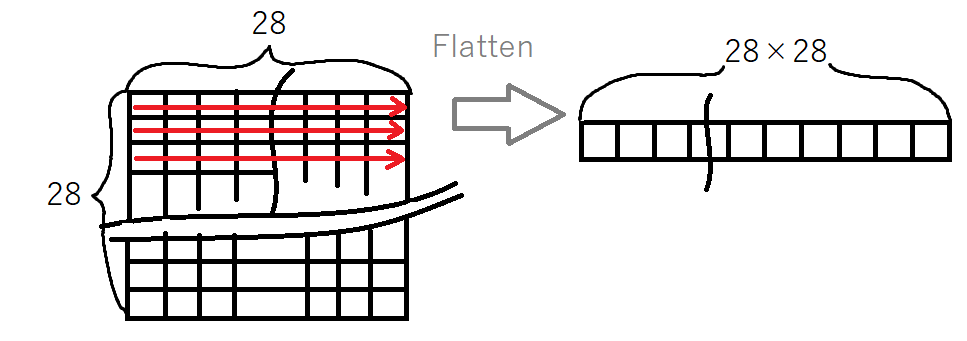
keras.layers.Flatten(input_shape=(28, 28)),
keras.layers.Dense(128, activation='relu'),
keras.layers.Dense(10, activation='softmax')
])「keras.layers」のように層を作成することができます。
入力層:画像の縦×横のピクセルを1次元配列として入力するため、「Flatten」で28×28のデータを1次元配列化しています。
中間層:Denseという機能で作成します。Denseは、「通常の全結合ニューラルネットワークレイヤー」というものを作成できるらしいです。全結合は、前の層からの出力が全ての全てのノードの入力となるように、結合されているような感じです。また、活性化関数は「relu」というものを指定しています。
出力層:同様に、Denseで作成します。全結合の層なので、中間層の出力が入力として全てのノードに接続されます。活性化関数は「softmax」関数を指定しています。基本的に、多クラス分類の時は「softmax」が利用されるようです。scikit-learnの多クラス分類時のMLPは、出力層の活性化関数が「softmax」固定でした。TensorFlowは指定できる分、自由度が高いです(と思います)。
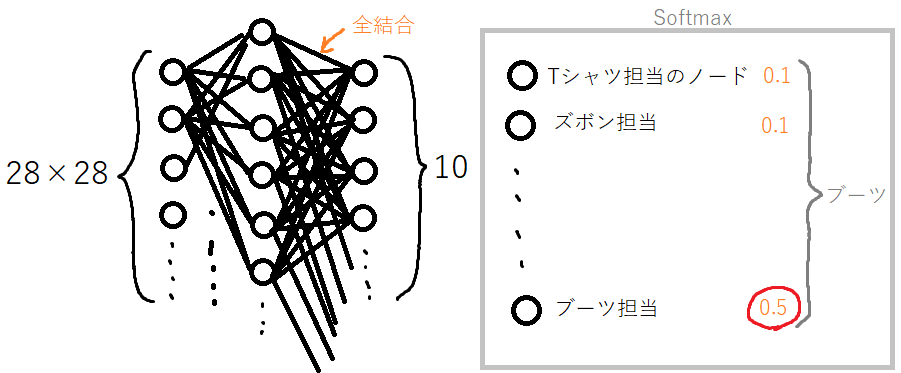
softmaxは、多クラスの答えを確率で出してくれるので、一番可能性が高いものが答えとなります。
モデルのコンパイル
コンパイルは、C言語とかのコンパイルとは少し違うイメージでした。この部分で、ニューラルネットワークの最適化設定を行うみたいです。
ニューラルネットワークでは、損失関数というものを最小化することで、最適なパラメータを探索しています。その部分のアルゴリズムを「adam」というものを利用すると設定したりします。
model.compile(optimizer='adam',
loss='sparse_categorical_crossentropy',
metrics=['accuracy'])この部分は理論的にももっと調べないと行けなさそうです。私の課題です。
実は、勾配降下法という最適化方法を勉強しています。説明ができるようになったらいつか記事にしたいです・・・
モデルの訓練
ほぼ、scikit-learnと同じですね。エポック数は、試行回数です。回数が多いほどより多くのパラメータを試すことができます。
model.fit(X_train, y_train, epochs=5)訓練では、エポック数の回数分、より良いパラメータを試行錯誤してくれます。また、最初に試すパラメータが毎回違うので、精度が出ないパラメータから始まると、5回目でもいまいちなパラメータになることもあります。
Epoch 1/5
1875/1875 [==============================] - 3s 2ms/step - loss: 0.5036 - accuracy: 0.8227
Epoch 2/5
1875/1875 [==============================] - 3s 2ms/step - loss: 0.3803 - accuracy: 0.8636
Epoch 3/5
1875/1875 [==============================] - 3s 2ms/step - loss: 0.3409 - accuracy: 0.8759
Epoch 4/5
1875/1875 [==============================] - 4s 2ms/step - loss: 0.3141 - accuracy: 0.8844
Epoch 5/5
1875/1875 [==============================] - 6s 3ms/step - loss: 0.2964 - accuracy: 0.8896
<tensorflow.python.keras.callbacks.History at 0x7f1c4acae550>チュートリアルでは、上の表示の1875が訓練データ数の60000となっていますが、どうやらバッチ単位(bartch_sizeパラメータで設定される、デフォルトでは32)の数字表記となったようです。
バッチサイズは、一回の最適化に使うデータ数です。32個のデータで最適化をして、より良いパラメータに変更して、次の32個のデータで最適化をして、みたいに繰り返します。
今回はデフォルトの32なので、32個のデータ毎に処理を行って1875回(全データ数32個×1875セット=60000個)という表記です。
test_loss, test_acc = model.evaluate(X_test, y_test, verbose=2)
print('\nTest accuracy:', test_acc)最後に、テストデータを与えて評価してみました。
313/313 - 0s - loss: 0.3534 - accuracy: 0.8722
Test accuracy: 0.8722000122070312だいたいチュートリアルと同じ87%となりました。チュートリアルより精度が落ちるのが悔しいので、エポック数を増やして力押ししてみました。
エポック数(試行回数)を増加させてみる
今度はエポック数を10回にしてみました。
model.fit(X_train, y_train, epochs=10)運よく、最初から89%の精度がでるパラメータになりましたので、前回よりも良いモデルチューニングとなりそうです。
Epoch 1/10
1875/1875 [==============================] - 4s 2ms/step - loss: 0.2807 - accuracy: 0.8974
Epoch 2/10
1875/1875 [==============================] - 4s 2ms/step - loss: 0.2688 - accuracy: 0.9010
Epoch 3/10
1875/1875 [==============================] - 4s 2ms/step - loss: 0.2568 - accuracy: 0.9037
Epoch 4/10
1875/1875 [==============================] - 4s 2ms/step - loss: 0.2475 - accuracy: 0.9068
Epoch 5/10
1875/1875 [==============================] - 4s 2ms/step - loss: 0.2392 - accuracy: 0.9093
Epoch 6/10
1875/1875 [==============================] - 4s 2ms/step - loss: 0.2310 - accuracy: 0.9130
Epoch 7/10
1875/1875 [==============================] - 4s 2ms/step - loss: 0.2249 - accuracy: 0.9156
Epoch 8/10
1875/1875 [==============================] - 4s 2ms/step - loss: 0.2182 - accuracy: 0.9177
Epoch 9/10
1875/1875 [==============================] - 4s 2ms/step - loss: 0.2133 - accuracy: 0.9198
Epoch 10/10
1875/1875 [==============================] - 4s 2ms/step - loss: 0.2070 - accuracy: 0.9230
<tensorflow.python.keras.callbacks.History at 0x7f1c3f89d780>訓練が完了したら、テストデータで評価を行います。
test_loss, test_acc = model.evaluate(X_test, y_test, verbose=2)
print('\nTest accuracy:', test_acc)313/313 - 0s - loss: 0.3519 - accuracy: 0.8812
Test accuracy: 0.8812000155448914前回の訓練よりも1%程良い精度を出すことができました。
ニューラルネットワークにおいて、より良い最適なパラメータを探索するために試行回数のエポック数を増やすことで精度の向上が望めそうです。
本格的にディープラーニングを始めると、この試行を早くたくさん行うために、良いグラフィックボードや外部接続のGPUを調達することになりそうです。
世の中、金っていうのも一理あるよね。
ディープラーニングには高価なGPUを導入している人もみたことがあるけど、まだそのレベルじゃないから大丈夫だね。