
MLPはさすがニューラルネットワークといったパラメータの多さです。
まずはデフォルトパラメータで分類問題をやってみたんだね。
パーセプトロン、多層パーセプトロンと概要を学んできました。数学的な背景などはほぼ深堀せずに見てきましたが、ライブラリに任せて、まずはやってみてどんなスコアが出るか調整という点が重要そうです。実は、勾配降下法や損失関数、活性化関数など、難しい言葉をいろいろと勉強してみたのですが、まだ腑に落ちていないというか、説明できる自信もないので、そっと心にしまっている所存でございます。今回は、乳がんデータ(2クラス分類問題)をscikit-learnで実装してみるところまでやってみます。
多層パーセプトロン(MLP)についてはこちらの記事もご参考ください。

こんな人の役に立つかも
・機械学習プログラミングを勉強している人
・scikit-learnでMLPを実装したい人
・多層パーセプロトンの勉強をしている人
MLPClassifierについて
scikit-learnの多層パーセプトロン分類器、MLPClassifierの全体像をまとめたいと思います。

入力層は特徴量の数分入力します。
中間層は、指定して増やしていくことができます。
出力層は、2クラス問題の場合、1個、多クラス問題の場合、クラス分の数が存在するみたいです。
中間層について
scikit-learnのMLPClassifierでは、パラメータ「hidden_layer_sizes」で中間層の構成を指定するこができます。デフォルトでは1つの中間層に100個のニューロンが存在しているような構成となります。
例えば、[4, 3]のように指定すると、次のような中間層を作成することができます。
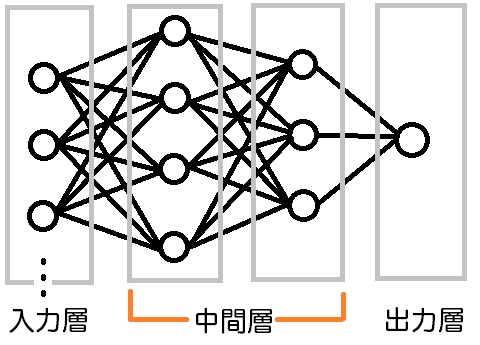
中間層は、多ければよいというものでもないらしいです。
また、中間層の「活性化関数」は、「activation」パラメータで設定できるようです。
出力層について
MLPClassifierでは、2クラス問題の時は、1個の出力をもち、活性化関数が「logistic」関数となるようです。
また、多クラス問題の時は、答えの数分の出力を持ち、活性化関数が「softmax」となるようです。
この、出力の数は、訓練させたMLPの
・n_outputs_:出力の個数
・out_activation_:出力の活性化関数
のパラメータで確認することができました。
乳がんデータをMLPで分類
まずは、乳がんデータをimportして、データを訓練用、テスト用に分割します。
from sklearn.datasets import load_breast_cancer
from sklearn.model_selection import train_test_split
import matplotlib.pyplot as plt
import numpy as np
import pandas as pd
panda_box = load_breast_cancer()
X = panda_box.data
y = panda_box.target
#訓練データとテストデータに分割
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size = 0.25, stratify=y, random_state=0)MLPを訓練させて、正解率を算出します。
from sklearn.neural_network import MLPClassifier
from sklearn.metrics import accuracy_score
#MLPを訓練
clf = MLPClassifier().fit(X_train,y_train)
#accuracy_scoreを使った場合
predict = clf.predict(X_test)
print("Accuracy")
print(accuracy_score(y_test, predict))
#こちらの表記でも可能です。
print(clf.score(X_test, y_test))Accuracy
0.9300699300699301
0.9300699300699301訓練するたびにスコアはばらつくので、20回繰り返しで見てみます。
score_array = []
for i in range(0, 20):
clf.fit(X_train,y_train)
score_array.append(clf.score(X_test, y_test))
plt.plot(score_array)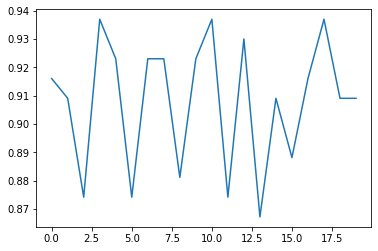
87%~94%の間の精度であることがわかりました。
出力の数、出力の活性化関数も確認してみました。
print(clf.n_outputs_)
print(clf.out_activation_)出力が1で、logisticの活性化関数であることがわかります。
1
logisticMLPって、データのスケーリング、大切じゃなかった??
ということで、標準化された乳がんデータでも行ってみました。
データの標準化をした場合
乳がんデータを標準化します。
標準化については、こちらの記事もご参考ください。

#標準化
from sklearn.preprocessing import StandardScaler
scaler = StandardScaler()
#訓練データをもとに標準化して訓練データを標準化
X_train_scaled = scaler.fit_transform(X_train)
X_test_scaled = scaler.transform(X_test)訓練データ「X_train」を「X_train_scaled」、テストデータ「X_test」を「X_test_scaled」という標準化されたデータへと変換しました。
続いて、標準化されたデータでMLPを訓練します。
clf = MLPClassifier().fit(X_train_scaled,y_train)
predict = clf.predict(X_test_scaled)
print("Accuracy")
print(accuracy_score(y_test, predict))Accuracy
0.958041958041958結構良いスコアが出ました。20回繰り返してみてみます。
score_array = []
for i in range(0, 20):
clf.fit(X_train_scaled,y_train)
score_array.append(clf.score(X_test_scaled, y_test))
plt.plot(score_array)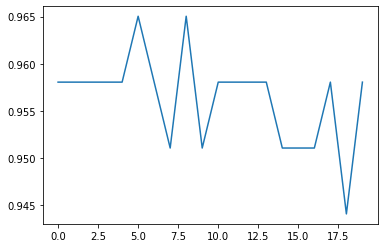
94%~96.5%の間のスコアとなり、データのスケーリングがMLPにかなり有効であることがわかりました。