
Digitデータをいろいろな分類器で試してみることにしました。
今までの復習とか、それぞれのアルゴリズムの違いがわかるかもね。
前回、初めての画像系の分類ということで、scikit-learnのデータセットであるDigitデータを確認しました。今回は、機械学習アルゴリズムで実際に分類してみようと思います。これまでにいくつか分類の機械学習アルゴリズムは勉強をしていますが、まず基本的なところで「k最近傍法」を思い出しつつ、使ってみたいと思います。
前回のdigitデータについての記事はこちらをご参考ください。

k最近傍法の過去の記事についてはこちらをご参考ください。

こんな人の役に立つかも
・機械学習プログラミングを勉強している人
・scikit-learnのdigitデータを分類したい人
・scikit-learnのdigitデータをk最近傍法で分類したい人
k最近傍法で分類
今まで勉強をした流れで、
・訓練データとテストデータへ分割
・交差検証でパラメータをチューニング
・アルゴリズムを訓練してテストデータで評価
という流れを行いたいと思います。
また、評価の時は、アルゴリズムのscoreで算出するのではなく、ConfusionMatrixと、ClassificationReportで行います。
importから
importからdigitデータの読み込み、訓練データとテストデータに分割するところまでの流れです。
from sklearn import datasets
from sklearn.model_selection import train_test_split
from sklearn.model_selection import cross_val_score
import numpy as np
#結果評価関連
from sklearn.metrics import confusion_matrix
from sklearn.metrics import classification_report
panda_box = datasets.load_digits()
X = panda_box.data
y = panda_box.target
#訓練データとテストデータに分割
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size = 0.25, stratify=y, random_state=0)次に、3分割交差検証を行います。まずは、k最近傍法のパラメータは、近傍の数「n_neighbors」を3としてみます。
from sklearn.neighbors import KNeighborsClassifier
#k-最近傍法
clf = KNeighborsClassifier(n_neighbors = 3)
#交差検証
score = cross_val_score(clf, X_train, y_train, cv=3)
#結果の表示
print("交差検証の結果")
print(score)
print("交差検証の平均")
print("{:.4f}".format(np.mean(score)))
#テストデータ評価
clf.fit(X_train, y_train)
predict = clf.predict(X_test)
print("==ClassificationReport==")
print(classification_report(y_test, predict,digits=4))適当に当てはめたパラメータでも98.67%も出ています。
交差検証の結果
[0.98663697 0.9844098 0.97772829]
交差検証の平均
0.9829
==ClassificationReport==
precision recall f1-score support
0 1.0000 1.0000 1.0000 45
1 0.9787 1.0000 0.9892 46
2 1.0000 1.0000 1.0000 44
3 0.9375 0.9783 0.9574 46
4 1.0000 0.9778 0.9888 45
5 1.0000 1.0000 1.0000 46
6 1.0000 1.0000 1.0000 45
7 0.9783 1.0000 0.9890 45
8 1.0000 0.9535 0.9762 43
9 0.9773 0.9556 0.9663 45
accuracy 0.9867 450
macro avg 0.9872 0.9865 0.9867 450
weighted avg 0.9870 0.9867 0.9867 450念の為、パラメータ「n_neighbors」が1〜30までで、どのようにスコアが変化していくかを次にようにmatplotlibでプロットして確認してみます。
import matplotlib.pyplot as plt
import numpy as np
train_dat_array = []
loop = 30
for i in range(loop):
clf = KNeighborsClassifier(n_neighbors=(i+1))
score = cross_val_score(clf, X_train, y_train, cv=3)
train_dat_array.append(np.mean(score))
#グラフ
X_axis = np.linspace(1,loop+1,loop)
plt.plot(X_axis, train_dat_array)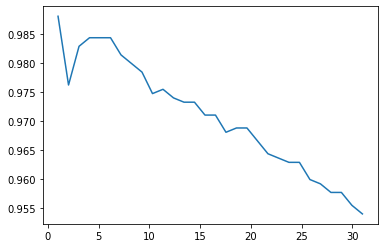
交差検証の結果、n_neighborsが5前後の時がスコアが高く、n_neighborsが増えるにつれてスコアが低下していきます。1の時は訓練データに過適合していそうなので、今回は5を選択します。
「5」とした場合でテストデータのスコアを出してみます。
clf = KNeighborsClassifier(n_neighbors = 5).fit(X_train, y_train)
#テストデータ評価
predict = clf.predict(X_test)
print("==ConfusionMatrix==")
print(confusion_matrix(y_test, predict))
print("==ClassificationReport==")
print(classification_report(y_test, predict,digits=4))==ConfusionMatrix==
[[45 0 0 0 0 0 0 0 0 0]
[ 0 46 0 0 0 0 0 0 0 0]
[ 0 1 43 0 0 0 0 0 0 0]
[ 0 0 0 44 0 0 0 1 1 0]
[ 0 0 0 0 44 0 0 0 1 0]
[ 0 0 0 0 0 46 0 0 0 0]
[ 0 0 0 0 0 0 45 0 0 0]
[ 0 0 0 0 0 0 0 45 0 0]
[ 0 1 0 1 0 0 0 0 41 0]
[ 0 0 0 2 0 1 0 0 0 42]]
==ClassificationReport==
precision recall f1-score support
0 1.0000 1.0000 1.0000 45
1 0.9583 1.0000 0.9787 46
2 1.0000 0.9773 0.9885 44
3 0.9362 0.9565 0.9462 46
4 1.0000 0.9778 0.9888 45
5 0.9787 1.0000 0.9892 46
6 1.0000 1.0000 1.0000 45
7 0.9783 1.0000 0.9890 45
8 0.9535 0.9535 0.9535 43
9 1.0000 0.9333 0.9655 45
accuracy 0.9800 450
macro avg 0.9805 0.9798 0.9799 450
weighted avg 0.9804 0.9800 0.9800 45098%と、若干、テストデータに対してはスコアが低下してしまいましたが、今回のテストデータの場合だと若干低下しているように見えるだけなのかもしれません。
ClassificationReportのaccuracy、0.9800という数値が今までscoreで出していたものと同じ数値となります。
試しに、アルゴリズムのscoreでもみてみますね。
print(clf.score(X_test, y_test))0.98同じ正解率を出しています。
正解率結構高い・・・
今回学んだこと
最初、私はテストデータへのスコアを見てパラメータを変化させていました。
しかし、実際テストデータへ合わせても、他のデータにすり替わったらその調整は意味のないものになってしまいます。
パラメータチューニングのために交差検証があるので、今回のように3から5へ交差検証の結果をみてパラメータチューニングをしたにも関わらず、テストデータでスコアが低下してしまったとしても、それは偶然今回のテストデータでスコアが低下してしまった可能性が高いです。
テストデータへのスコアをみてパラメータを変更させては意味がない、勉強しました。